![image]()
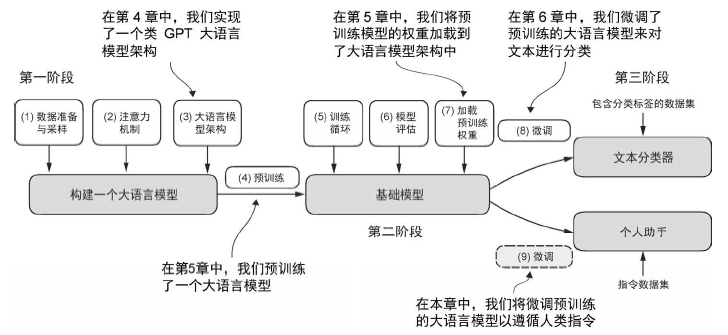
指令微调
大语言模型的预训练是通过让模型学会逐个生成单词来实现的。预训练后的大语言模型能够进行文本补全,这意味着给定任意一个片段作为输入,模型能够生成一个句子或撰写一个段落。
为有监督指令微调准备数据集
指令微调需要在一个明确提供输入-输出对(如同从JSON 文件中提取的各个样本)的数据集上训练模型。在获得这些样本后,有多种方法可以将样本制作成适用于大语言模型的格式。
![image]()
将数据组织成训练批次
在上一章中,训练批次是通过 PyTorch 的 DataLoader 类自动创建的,该类使用默认的聚合(collate)函数将样本列表组合成训练批次。聚合函数的作用是将单个数据样本列表合并为一个批次,以便模型在训练时能够高效地处理。
然而,指令微调的批次处理稍微有些复杂,因为需要创建一个自定义的聚合函数,然后再将其集成到 DataLoader 中。我们将实现这个自定义聚合函数,以满足指令微调数据集的特定需求和格式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import torch
from torch.utils.data import Dataset
class InstructionDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.encoded_texts = []
for entry in data:
instruction_plus_input = format_input(entry)
response_text = f"\n\n### Response:\n{entry['output']}"
full_text = instruction_plus_input + response_text
self.encoded_texts.append(
tokenizer.encode(full_text)
)
def __getitem__(self, index):
return self.encoded_texts[index]
def __len__(self):
return len(self.data)
|
在商议章中,我们将数据集中的所有例子填充为相同的长度。
- 而在这里,我们采取了一种更为复杂的方法: 开发了一个自定义的 “collate” 函数,并将其传递给数据加载器。
- 这个自定义的 collate 函数会将每个批次中的训练示例填充到相同的长度(不同批次的长度可以不同),代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def custom_collate_draft_1(
batch,
pad_token_id=50256,
device="cpu"
):
batch_max_length = max(len(item)+1 for item in batch)
inputs_lst = []
for item in batch:
new_item = item.copy()
new_item += [pad_token_id]
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1])
inputs_lst.append(inputs)
inputs_tensor = torch.stack(inputs_lst).to(device)
return inputs_tensor
|
上述代码只整合了输入的 token,还需要将输出的 token 也加到数据中(使用现有的训练框架就不用自己实现输出):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def custom_collate_draft_2(
batch,
pad_token_id=50256,
device="cpu"
):
batch_max_length = max(len(item)+1 for item in batch)
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
new_item += [pad_token_id]
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1])
targets = torch.tensor(padded[1:])
inputs_lst.append(inputs)
targets_lst.append(targets)
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
|
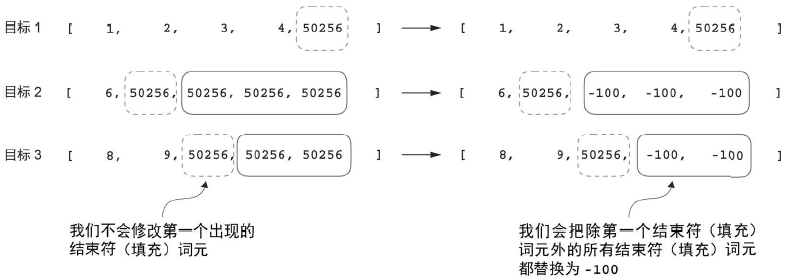
接下来,引入了一个 ignore_index 值,用于将所有填充 token 的ID替换为一个新值;引入 ignore_index 的目的是使我们能够在损失函数中忽略填充值。
具体来说,这意味着我们将 50256 对应的 token ID替换为 -100,如图所示。(分类微调时无须担心这个问题,因为我们只根据最后的输出词元对模型进行训练。)
不过,值得注意的是,我们在目标列表中保留了一个结束符词元,ID 为 50256,如图所示。保留此词元有助于大语言模型学会何时根据指令生成结束符词元,一般我们将其作为生成的回复已经完成的指示符。
![image]()
完整的代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
def custom_collate_fn(
batch,
pad_token_id=50256,
ignore_index=-100,
allowed_max_length=None,
device="cpu"
):
batch_max_length = max(len(item)+1 for item in batch)
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
new_item += [pad_token_id]
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1])
targets = torch.tensor(padded[1:])
mask = targets == pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]
targets = targets[:allowed_max_length]
inputs_lst.append(inputs)
targets_lst.append(targets)
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
|
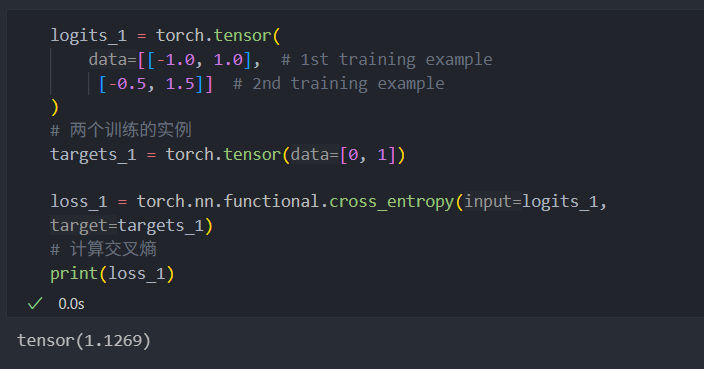
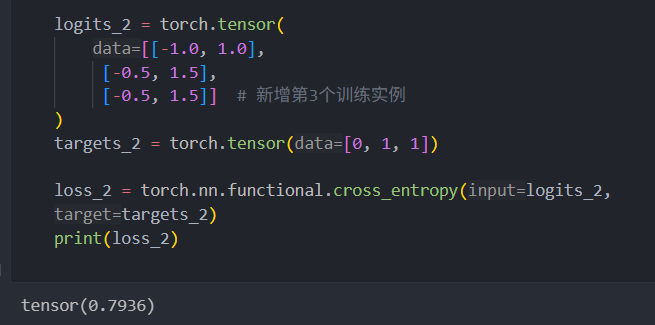
关于为什么要用 -100 替换填充 token:
两个例子,如果多一个 token 会影响 loss 的计算
![image]()
![image]()
在 PyTorch 中,交叉熵函数的默认设置为cross_entropy(…, ignore_index=-100)。这意味着它会忽略 token 为 -100 的目标。我们利用这个ignore_index 来忽略那些用于填充训练示例以使每个批次具有相同长度的额外结束符(填充)词元。
除了掩码填充词元,实践中我们通常还会掩码与指令相关的目标词元,如图所示。通过掩码与指令对应的目标词元,交叉熵损失可以仅针对生成的回复目标词元进行计算。因此,模型的训练更专注于生成准确的回复,而非记住指令,这样可以帮助减少过拟合。(本章并不 mask prompt)
![image]()
创建指令数据集的数据加载器
加载数据集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=True,
drop_last=True,
num_workers=num_workers
)
|
加载预训练的大模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| from gpt_download import download_and_load_gpt2
from previous_chapters import GPTModel, load_weights_into_gpt
BASE_CONFIG = {
"vocab_size": 50257,
"context_length": 1024,
"drop_rate": 0.0,
"qkv_bias": True
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()
|