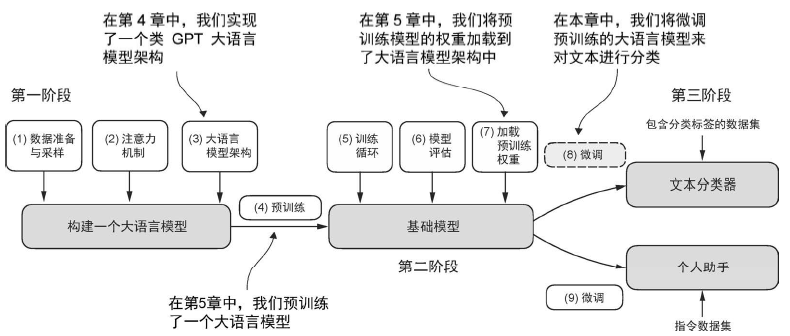
不同类型的微调 微调语言模型最常见的方法是指令微调和分类微调。
指令微调涉及使用特定的指令数据对一组任务进行训练,以提高语言模型理解和执行自然语言提示词中描述的任务的能力。
分类微调,即模型被训练来识别一组特定的类别标签,比如在消息中过滤“垃圾消息”和“非垃圾消息”。这类任务的例子不仅限于大语言模型和电子邮件过滤,还包括从图像中识别不同的植物种类,将新闻文章分类为体育、政治、科技等主题,以及在医学影像中区分良性肿瘤和恶性肿瘤。
经过指令微调的模型通常能够执行更广泛的任务。我们可以将分类微调模型视为高度专业化的模型。一般来说,开发一个专业化的模型比开发在多种任务中表现良好的通用模型更简单。
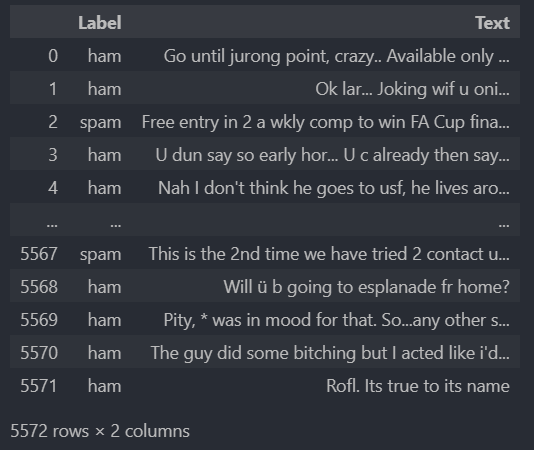
准备数据集 下载好的数据集为一个 tsv(csv)文件,包含两列:
其中正常的样本(ham)多于异常样本(spam),这里做了一个下采样:
1 2 3 4 5 6 7 8 9 10 11 12 def create_balanced_dataset (df ): num_spam = df[df["Label" ] == "spam" ].shape[0 ] ham_subset = df[df["Label" ] == "ham" ].sample(num_spam, random_state=123 ) balanced_df = pd.concat([ham_subset, df[df["Label" ] == "spam" ]]) return balanced_df balanced_df = create_balanced_dataset(df) print (balanced_df["Label" ].value_counts())
把标签 “ham” 和 “spam” 转换为整数类标签 “0” 和 “1” :
1 balanced_df["Label" ] = balanced_df["Label" ].map ({"ham" : 0 , "spam" : 1 })
相当于这个任务中只处理两个 token,即 0 和 1。
接下来划分训练集、验证集、测试集(或许可以直接用 Dataset 类):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def random_split (df, train_frac, validation_frac ): df = df.sample(frac=1 , random_state=123 ).reset_index(drop=True ) train_end = int (len (df) * train_frac) validation_end = train_end + int (len (df) * validation_frac) train_df = df[:train_end] validation_df = df[train_end:validation_end] test_df = df[validation_end:] return train_df, validation_df, test_df train_df, validation_df, test_df = random_split(balanced_df, 0.7 , 0.1 ) train_df.to_csv("train.csv" , index=None ) validation_df.to_csv("validation.csv" , index=None ) test_df.to_csv("test.csv" , index=None )
创建数据加载器 预训练时,是利用滑动窗口技术来生成统一大小的文本块,然后将其分组为批次,以便更高效地训练模型。每个块可以作为一个独立的训练实例。然而,现在我们处理的是包含不同长度文本 消息的垃圾消息数据集。为了像处理文本块那样对这些消息进行批处理,我们有以下两种方案可供选择:
将所有消息截断到数据集中最短消息的长度或批次长度
将所有消息填充到数据集中最长消息的长度或批次长度
第一种方法可能会导致信息丢失。所以使用第二种方法。为了实现批处理,将所有消息填充到数据集中最长消息的长度,需要向所有较短的消息添加填充词元。为此,可以使用”<|endoftext|>”作为填充词元。
以下 SpamDataset 类用于处理几个关键任务:
识别训练数据集中最长的序列
编码文本消息
确保所有其他序列都使用填充词元进行填充,以匹配最长序列的长度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import torchfrom torch.utils.data import Datasetclass SpamDataset (Dataset ): def __init__ (self, csv_file, tokenizer, max_length=None , pad_token_id=50256 ): self .data = pd.read_csv(csv_file) self .encoded_texts = [ tokenizer.encode(text) for text in self .data["Text" ] ] if max_length is None : self .max_length = self ._longest_encoded_length() else : self .max_length = max_length self .encoded_texts = [ encoded_text[:self .max_length] for encoded_text in self .encoded_texts ] self .encoded_texts = [ encoded_text + [pad_token_id] * (self .max_length - len (encoded_text)) for encoded_text in self .encoded_texts ] def __getitem__ (self, index ): encoded = self .encoded_texts[index] label = self .data.iloc[index]["Label" ] return ( torch.tensor(encoded, dtype=torch.long), torch.tensor(label, dtype=torch.long) ) def __len__ (self ): return len (self .data) def _longest_encoded_length (self ): max_length = 0 for encoded_text in self .encoded_texts: encoded_length = len (encoded_text) if encoded_length > max_length: max_length = encoded_length return max_length
注意这个类中的 _longest_encoded_length 方法:函数或变量名前加下划线 _,是一种“命名约定”,。它用来表达“这个函数/变量是内部使用的(private)”,不希望被外部直接访问。
接下来使用 Dataloader 来加载数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from torch.utils.data import DataLoadernum_workers = 0 batch_size = 8 torch.manual_seed(123 ) train_dataset = SpamDataset( csv_file="train.csv" , max_length=None , tokenizer=tokenizer ) train_loader = DataLoader( dataset=train_dataset, batch_size=batch_size, shuffle=True , num_workers=num_workers, drop_last=True , )
初始化带有预训练权重的模型 使用前面提到的方法加载 OpenAI 的 GPT-2 权重,并进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 text_2 = ( "Is the following text 'spam'? Answer with 'yes' or 'no':" " 'You are a winner you have been specially" " selected to receive $1000 cash or a $2000 award.'" ) token_ids = generate_text_simple( model=model, idx=text_to_token_ids(text_2, tokenizer), max_new_tokens=23 , context_size=BASE_CONFIG["context_length" ] ) print (token_ids_to_text(token_ids, tokenizer))
输出为:
根据输出结果,显然模型在遵循指令方面存在困难。这一结果是预期中的,因为模型仅经过了预训练,缺乏指令微调。因此,让我们为分类微调准备模型。
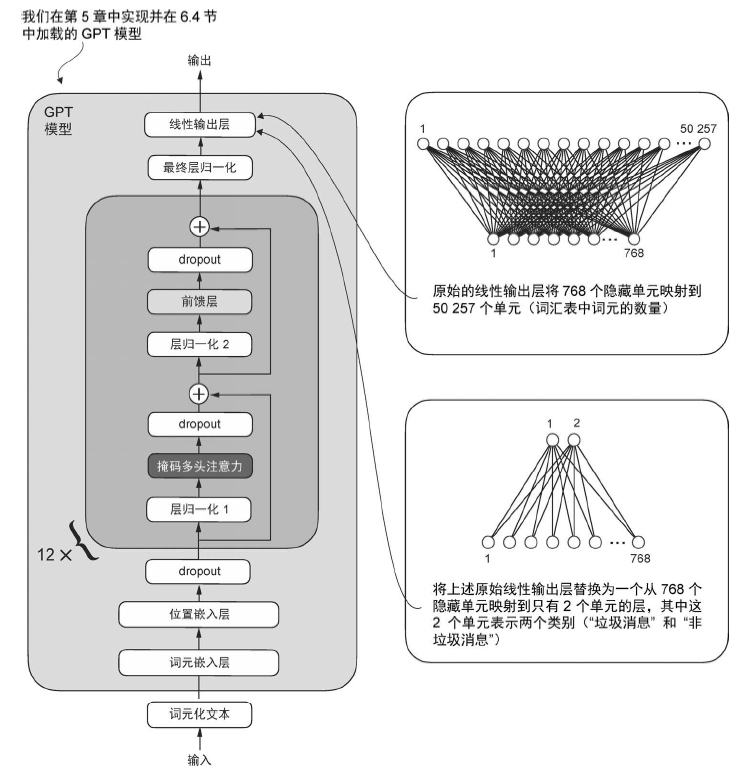
添加分类头 我们需要修改预训练的大语言模型来为分类微调做好准备。为了实现这一点,我们将原始输出层(该输出层会将隐藏表示映射到一张包含50 257 个词汇的词汇表中)替换为一个较小的输出层,该输出层会映射到两个类别:0(“非垃圾消息”)和1(“垃圾消息”),如图所示:
原始的模型结构为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 GPTModel( (tok_emb): Embedding(50257, 768) (pos_emb): Embedding(1024, 768) (drop_emb): Dropout(p=0.0, inplace=False) (trf_blocks): Sequential( (0): TransformerBlock( (att): MultiHeadAttention( (W_query): Linear(in_features=768, out_features=768, bias=True) (W_key): Linear(in_features=768, out_features=768, bias=True) (W_value): Linear(in_features=768, out_features=768, bias=True) (out_proj): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.0, inplace=False) ) (ff): FeedForward( (layers): Sequential( (0): Linear(in_features=768, out_features=3072, bias=True) (1): GELU() (2): Linear(in_features=3072, out_features=768, bias=True) ) ) (norm1): LayerNorm() (norm2): LayerNorm() (drop_resid): Dropout(p=0.0, inplace=False) ) (1): TransformerBlock( ... ) (final_norm): LayerNorm() (out_head): Linear(in_features=768, out_features=50257, bias=False) ) )
由于模型已经经过了预训练,因此不需要微调所有的模型层。在基于神经网络的语言模型中,较低层通常捕捉基本的语言结构和语义,适用于广泛的任务和数据集,最后几层(靠近输出的层)更侧重于捕捉细微的语言模式和特定任务的特征。因此,只微调最后几层通常就足以将模型适应到新任务。
这里只微调最后的分类头以及最后一个 transformer 层,所以我们需要先冻结所有的参数,然后再将最后的输出层进行替换:
1 2 3 4 5 6 7 for param in model.parameters(): param.requires_grad = False torch.manual_seed(123 ) num_classes = 2 model.out_head = torch.nn.Linear(in_features=BASE_CONFIG["emb_dim" ], out_features=num_classes)
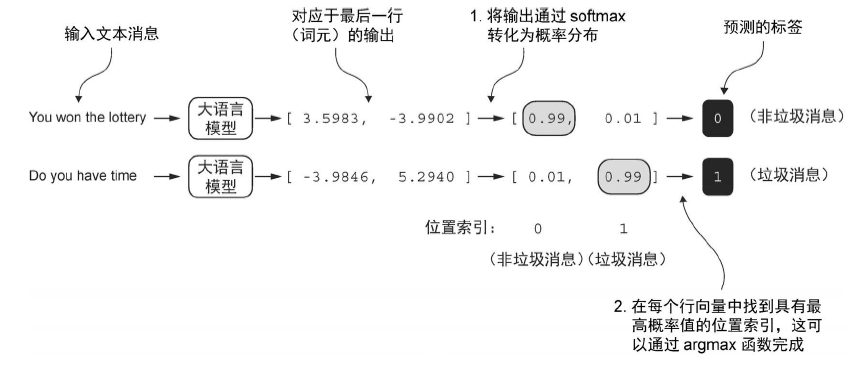
此时我们只需要关注输出序列的最后一个 token:
之前探讨过注意力机制,它建立了每个输入词元与其他输入词元之间的关系,以及因果注意力掩码的概念,这在类 GPT 模型中经常使用
这种掩码限制了一个词元的关注范围 ,即它只能关注当前及之前的位置,从而确保每个词元只受自己和之前词元 的影响
序列中的最后一个词元累积了最多的信息,因为它是唯一一个可以访问之前所有数据的词元。因此,在垃圾消息分类任务中,我们在微调过程中会关注这个最后的词元
计算分类损失和准确率 之前通过将 50257 个输出转换为概率(利用 softmax 函数),然后返回最高概率的位置(利用 argmax 函数),来计算大语言模型生成的下一个 token id。在这里,采取相同的方法来计算模型对于给定输入是预测为“垃圾消息”还是“非垃圾消息”,唯一的区别是处理的是 2 维而不是 50257 维的输出:
这里实际上是一个分类任务(二分类),而不是回归任务(例如 VAD)
同样选取分数最高的 token 作为输出(这里只有 2 个 token)。然后使用以下代码计算精确率:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def calc_accuracy_loader (data_loader, model, device, num_batches=None ): model.eval () correct_predictions, num_examples = 0 , 0 if num_batches is None : num_batches = len (data_loader) else : num_batches = min (num_batches, len (data_loader)) for i, (input_batch, target_batch) in enumerate (data_loader): if i < num_batches: input_batch, target_batch = input_batch.to(device), target_batch.to(device) with torch.no_grad(): logits = model(input_batch)[:, -1 , :] predicted_labels = torch.argmax(logits, dim=-1 ) num_examples += predicted_labels.shape[0 ] correct_predictions += (predicted_labels == target_batch).sum ().item() else : break return correct_predictions / num_examples
输出为:
1 2 3 4 Running on cuda device. Training accuracy: 46.25% Validation accuracy: 45.00% Test accuracy: 48.75%
可以看到,预测准确率接近随机预测,在这种情况下为50%。为了提高预测准确率,需要对模型进行微调。
然而,在开始微调模型之前,需要定义训练期间要优化的损失函数。我们的目标是最大化模型的垃圾消息分类准确率,这意味着前面的代码应该输出正确的类别标签:0 表示非垃圾消息,1 表示垃圾消息。
由于分类准确率不是一个可微分的函数,这里我们使用交叉熵损失作为替代来最大化准确率:
1 2 3 4 5 6 def calc_loss_batch (input_batch, target_batch, model, device ): input_batch, target_batch = input_batch.to(device), target_batch.to(device) logits = model(input_batch)[:, -1 , :] loss = torch.nn.functional.cross_entropy(logits, target_batch) return loss
在有监督数据上微调模型 核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 def train_classifier_simple (model, train_loader, val_loader, optimizer, device, num_epochs, eval_freq, eval_iter ): train_losses, val_losses, train_accs, val_accs = [], [], [], [] examples_seen, global_step = 0 , -1 for epoch in range (num_epochs): model.train() for input_batch, target_batch in train_loader: optimizer.zero_grad() loss = calc_loss_batch(input_batch, target_batch, model, device) loss.backward() optimizer.step() examples_seen += input_batch.shape[0 ] global_step += 1 if global_step % eval_freq == 0 : train_loss, val_loss = evaluate_model( model, train_loader, val_loader, device, eval_iter) train_losses.append(train_loss) val_losses.append(val_loss) print (f"Ep {epoch+1 } (Step {global_step:06d} ): " f"Train loss {train_loss:.3 f} , Val loss {val_loss:.3 f} " ) train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter) val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter) print (f"Training accuracy: {train_accuracy*100 :.2 f} % | " , end="" ) print (f"Validation accuracy: {val_accuracy*100 :.2 f} %" ) train_accs.append(train_accuracy) val_accs.append(val_accuracy) return train_losses, val_losses, train_accs, val_accs, examples_seen def evaluate_model (model, train_loader, val_loader, device, eval_iter ): model.eval () with torch.no_grad(): train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter) val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter) model.train() return train_loss, val_loss
训练的核心循环为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import timestart_time = time.time() torch.manual_seed(123 ) optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5 , weight_decay=0.1 ) num_epochs = 5 train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple( model, train_loader, val_loader, optimizer, device, num_epochs=num_epochs, eval_freq=50 , eval_iter=5 , ) end_time = time.time() execution_time_minutes = (end_time - start_time) / 60 print (f"Training completed in {execution_time_minutes:.2 f} minutes." )
输出为:
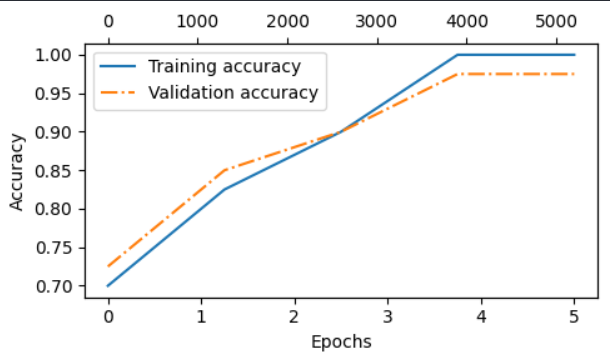
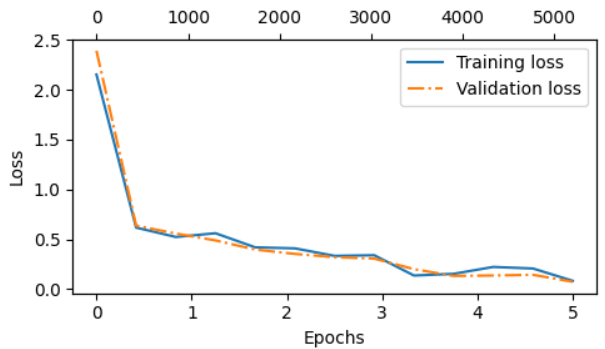
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392 Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637 Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557 Training accuracy: 70.00% | Validation accuracy: 72.50% Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489 Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397 Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353 Training accuracy: 82.50% | Validation accuracy: 85.00% Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320 Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306 Training accuracy: 90.00% | Validation accuracy: 90.00% Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200 Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132 Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137 Training accuracy: 100.00% | Validation accuracy: 97.50% Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143 Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074 Training accuracy: 100.00% | Validation accuracy: 97.50% Training completed in 0.56 minutes.
绘制出精确率和 loss 曲线:
使用 LLM 作为垃圾消息分类器 测试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def classify_review (text, model, tokenizer, device, max_length=None , pad_token_id=50256 ): model.eval () input_ids = tokenizer.encode(text) supported_context_length = model.pos_emb.weight.shape[0 ] input_ids = input_ids[:min (max_length, supported_context_length)] input_ids += [pad_token_id] * (max_length - len (input_ids)) input_tensor = torch.tensor(input_ids, device=device).unsqueeze(0 ) with torch.no_grad(): logits = model(input_tensor)[:, -1 , :] predicted_label = torch.argmax(logits, dim=-1 ).item() return "spam" if predicted_label == 1 else "not spam"
输出: