
评估文本生成模型
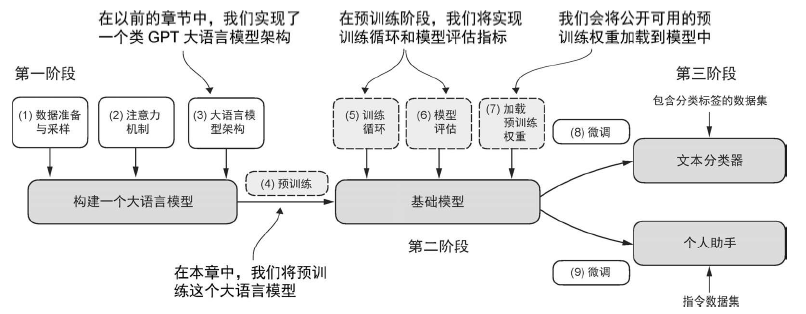
在训练之前,模型会生成随机的下一个词元的概率向量。模型训练的目标是确保与图中框出的目标词元 ID 对应的概率值被最大化。
训练大语言模型的目标是最大化正确词元的可能性,这涉及增大其相对于其他词元的概率。通过这种方式,可以确保大语言模型始终选择目标词元(实质上是句子中的下一个单词)作为它生成的下一个词元。
训练大语言模型
简单的代码框架如下:
1 | def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs, |
控制随机性的解码策略
上一章末尾定义的 generate_text_simple 函数,生成的词元是从词汇表的所有词元中选择概率分数最大的那一个。这意味着,即使在相同的起始上下文(Every effort moves you)中多次运行前面的 generate_text_simple 函数,大语言模型也将始终生成相同的输出。代码如下:
1 | def generate_text_simple(model, idx, max_new_tokens, context_size): |
温度缩放(Temperature)
前面的方法是使用 torch.argmax(也称为贪婪解码)来采样具有最高概率的词元作为下一个词元。为了生成更多样化的文本,可以用一个从概率分布(这里是大语言模型在每个词元生成步骤为每个词汇条目生成的概率分数)中采样的函数来取代 argmax。为了实现一个概率采样过程,现在可以用 PyTorch 中的 multinomial 函数替换 argmax:
1 | next_token_id = torch.multinomial(probas, num_samples=1).item() |
torch.multinomial 是 PyTorch 中用于多项分布采样(Multinomial Sampling)的函数,常用于根据概率分布从离散集合中随机抽取索引。它的核心功能是:给定一组权重(或概率),按照这些权重的比例随机采样若干个样本索引。
这里设置了 num_samples=1,所以本质上是采样,而不是选最大
通过一个称为温度缩放的概念,可以进一步控制分布和选择过程。温度缩放指的是将 logits 除以一个大于 0 的数。所有 logits 都除以相同的数(temperature),但 softmax 是一个非线性函数,而非线性变换对数值缩放的敏感性,使得 “都除以相同的数字” 并不会让比例保持完全相同。

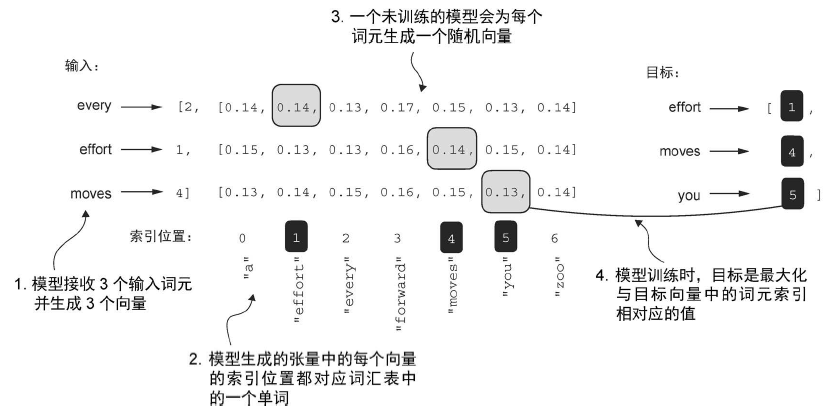
一个例子:从结果中可以看出,当温度设置为 0.1 时,概率分布变得更加陡峭,接近于 torch.argmax 的行为,因此最可能的 token 几乎总是被选中
Top-k 采样
较高的温度值会导致下一个词元的概率分布更均匀,从而产生更多样化的输出,因为它降低了模型重复选择最可能词元的可能性。这种方法允许探索概率较低但可能更具创造性和趣味性的生成路径。然而,这种方法的一个缺点是,它有时会导致语法不正确或完全无意义的输出。
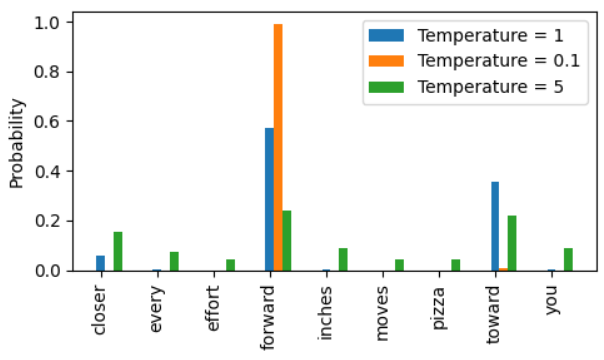
通过与概率采样和温度缩放相结合,Top-k 采样可以改善文本生成结果。在 Top-k 采样中,可以将采样的词元限制在前 k 个最可能的词元上,并通过掩码概率分数的方式来排除其他词元。
Top-k 方法用负无穷值(-inf)替换所有未选择的 logits,因此在计算 softmax 值时,非前 k 词元的概率分数为 0,剩余的概率总和为 1。
新的文本生成函数
1 | def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None): |
可以理解为:
- 温度校正是更加平滑,防止数据差之毫厘以谬以千里
- topK 是防止臭鱼烂虾进入筛选范围提高质量
加载和保存模型
保存
1 | torch.save(model.state_dict(), "model.pth") |
加载
1 | model = GPTModel(GPT_CONFIG_124M) |
像 AdamW 这样的自适应优化器可以为每个模型权重存储额外的参数。AdamW 可以使用历史数据动态地调整每个模型参数的学习率。如果没有它,那么优化器就会重置,模型可能学习效果不佳,甚至无法正确收敛,这意味着模型将失去生成连贯文本的能力。可以使用 torch.save 保存模型和优化器的 state_dict 内容:
1 | torch.save({ |
加载优化器和模型的参数:
1 | checkpoint = torch.load("model_and_optimizer.pth", weights_only=True) |
加载 GPT-2 权重
1 | import numpy as np |
默认情况下,GPTModel 实例使用随机权重初始化以进行预训练。使用 OpenAI 的模型权重的最后一步是用加载到 params 字典中的权重覆盖这些随机权重。为此,首先需要定义一个小的 assign 工具函数,该函数会检查两个张量或数组(left 和right)是否具有相同的维度或形状,并将 right 张量返回为可训练的 PyTorch 参数。