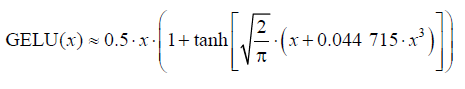【LLM From Scratch】3-从头实现 GPT 模型进行文本生成
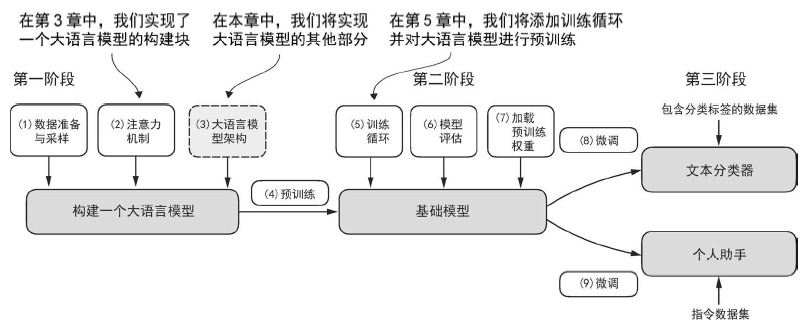
构建一个大语言模型架构 大语言模型包含以下内容:
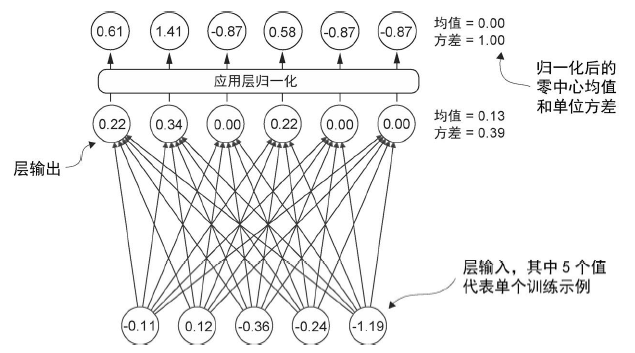
使用层归一化进行归一化激活 层归一化的主要思想是调整神经网络层的激活(输出),使其均值为 0 且方差(单位方差)为 1。这种调整有助于加速权重的有效收敛,并确保训练过程的一致性和可靠性。
注意,上图中的输入表示一个输入,层归一化是在特征维度进行。代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 class LayerNorm (nn.Module): def __init__ (self, emb_dim ): super ().__init__() self .eps = 1e-5 self .scale = nn.Parameter(torch.ones(emb_dim)) self .shift = nn.Parameter(torch.zeros(emb_dim)) def forward (self, x ): mean = x.mean(dim=-1 , keepdim=True ) var = x.var(dim=-1 , keepdim=True , unbiased=False ) norm_x = (x - mean) / torch.sqrt(var + self .eps) return self .scale * norm_x + self .shift
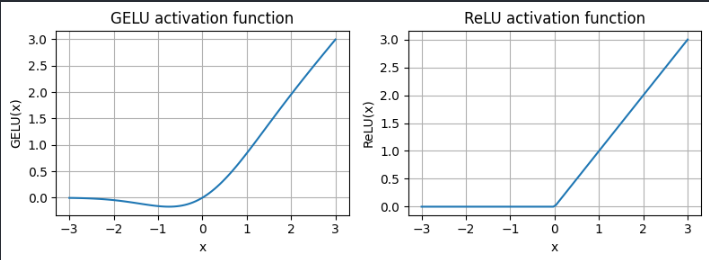
实现具有 GELU 激活函数的前馈神经网络 GELU 和 SwiGLU 是更为复杂且平滑的激活函数,分别结合了高斯分布和 sigmoid 门控线性单元。与较为简单的 ReLU 激活函数相比,它们能够提升深度学习模型的性能。一种近似实现如下:
1 2 3 4 5 6 7 8 9 10 class GELU (nn.Module): def __init__ (self ): super ().__init__() def forward (self, x ): return 0.5 * x * (1 + torch.tanh( torch.sqrt(torch.tensor(2.0 / torch.pi)) * (x + 0.044715 * torch.pow (x, 3 )) ))
对比 GELU 和 ReLU:
GELU 的平滑特性可以在训练过程中带来更好的优化效果,因为它允许模型参数进行更细微的调整。相比之下,ReLU 在零点处有一个尖锐的拐角,有时会使得优化过程更加困难,特别是在深度或复杂的网络结构中。此外,ReLU 对负输入的输出为0,而 GELU 对负输入会输出一个小的非零值。这意味着在训练过程中,接收到负输入的神经元仍然可以参与学习,只是贡献程度不如正输入大。
接下来定义前馈网络:
1 2 3 4 5 6 7 8 9 10 11 class FeedForward (nn.Module): def __init__ (self, cfg ): super ().__init__() self .layers = nn.Sequential( nn.Linear(cfg["emb_dim" ], 4 * cfg["emb_dim" ]), GELU(), nn.Linear(4 * cfg["emb_dim" ], cfg["emb_dim" ]), ) def forward (self, x ): return self .layers(x)
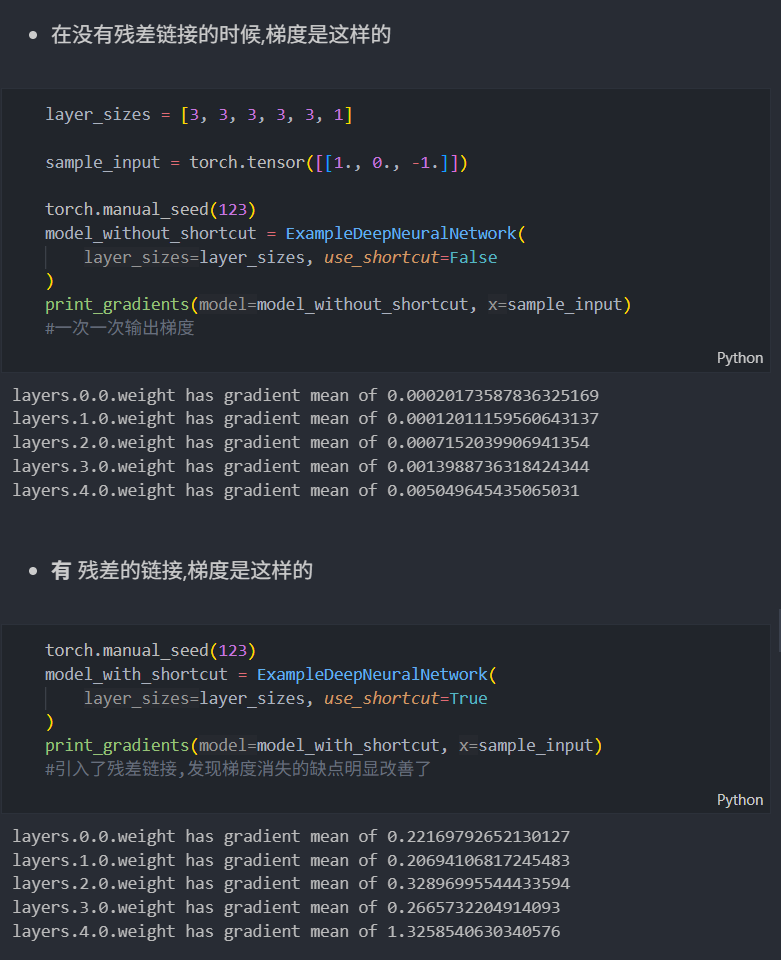
添加快捷连接(残差) 用于计算机视觉中的深度网络(特别是残差网络),目的是缓解梯度消失问题。梯度消失问题指的是在训练过程中,梯度在反向传播时逐渐变小,导致早期网络层难以有效训练。
对比:
代码如下:
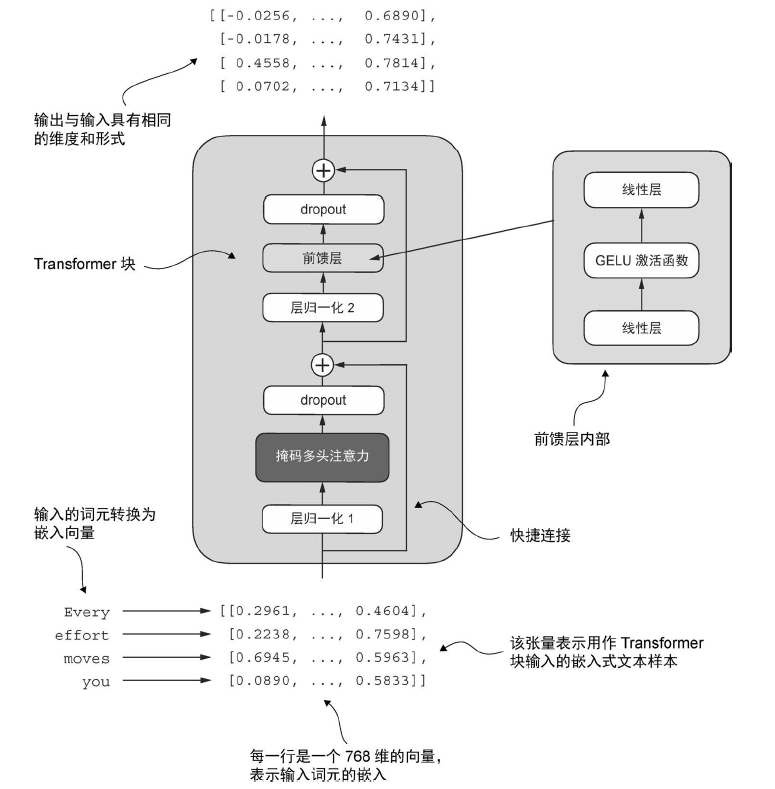
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class TransformerBlock (nn.Module): def __init__ (self, cfg ): super ().__init__() self .att = MultiHeadAttention( d_in=cfg["emb_dim" ], d_out=cfg["emb_dim" ], context_length=cfg["context_length" ], num_heads=cfg["n_heads" ], dropout=cfg["drop_rate" ], qkv_bias=cfg["qkv_bias" ] ) self .ff = FeedForward(cfg) self .norm1 = LayerNorm(cfg["emb_dim" ]) self .norm2 = LayerNorm(cfg["emb_dim" ]) self .drop_shortcut = nn.Dropout(cfg["drop_rate" ]) def forward (self, x ): shortcut = x x = self .norm1(x) x = self .att(x) x = self .drop_shortcut(x) x = x + shortcut shortcut = x x = self .norm2(x) x = self .ff(x) x = self .drop_shortcut(x) x = x + shortcut return x
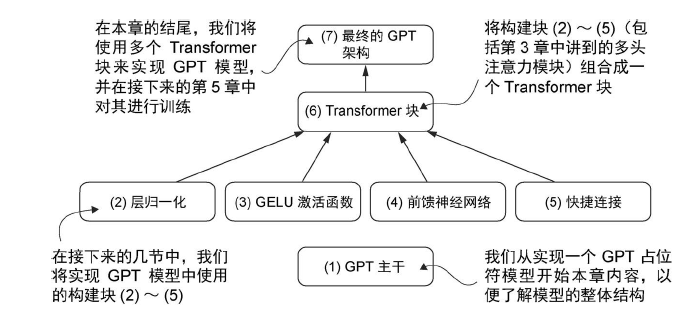
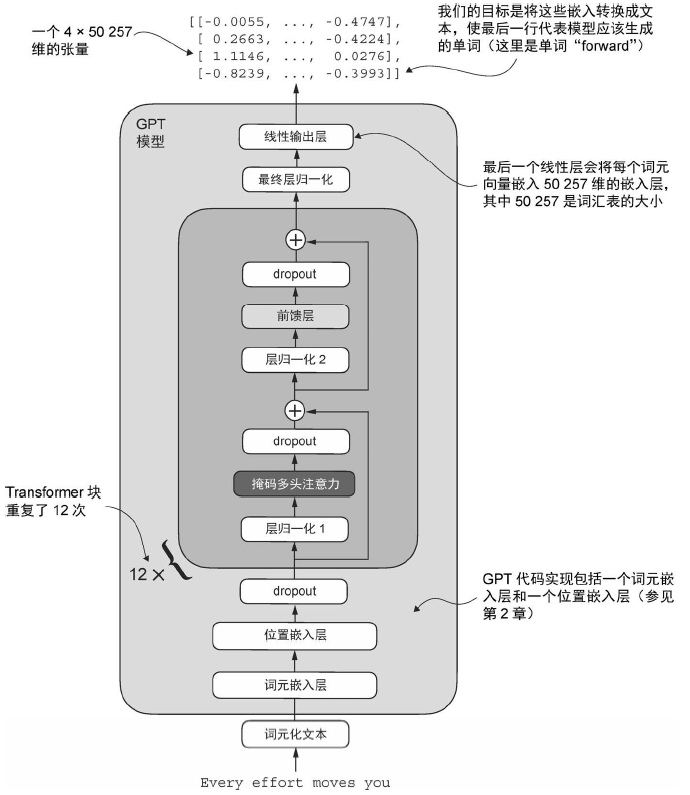
实现 GPT 模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class GPTModel (nn.Module): def __init__ (self, cfg ): super ().__init__() self .tok_emb = nn.Embedding(cfg["vocab_size" ], cfg["emb_dim" ]) self .pos_emb = nn.Embedding(cfg["context_length" ], cfg["emb_dim" ]) self .drop_emb = nn.Dropout(cfg["drop_rate" ]) self .trf_blocks = nn.Sequential( *[TransformerBlock(cfg) for _ in range (cfg["n_layers" ])]) self .trf_blocks = nn.Sequential( TransformerBlock(cfg), TransformerBlock(cfg), TransformerBlock(cfg) ) self .final_norm = LayerNorm(cfg["emb_dim" ]) self .out_head = nn.Linear( cfg["emb_dim" ], cfg["vocab_size" ], bias=False ) def forward (self, in_idx ): batch_size, seq_len = in_idx.shape tok_embeds = self .tok_emb(in_idx) pos_embeds = self .pos_emb(torch.arange(seq_len, device=in_idx.device)) x = tok_embeds + pos_embeds x = self .drop_emb(x) x = self .trf_blocks(x) x = self .final_norm(x) logits = self .out_head(x) return logits
可以通过以下代码计算模型参数:
1 2 3 total_params = sum (p.numel() for p in model.parameters()) print (f"Total number of parameters: {total_params:,} " )
发现输出大概为 1.6 亿。这是因为在原始 GPT-2 论文中,研究人员采用了权重共享 (weight tying)技术,即将标记嵌入层(tok_emb)作为输出层复用,具体表现为设置 self.out_head.weight = self.tok_emb.weight。
文本生成
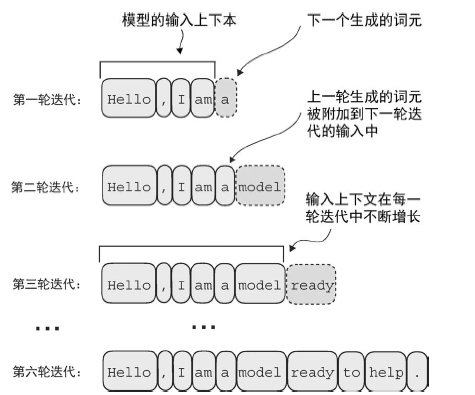
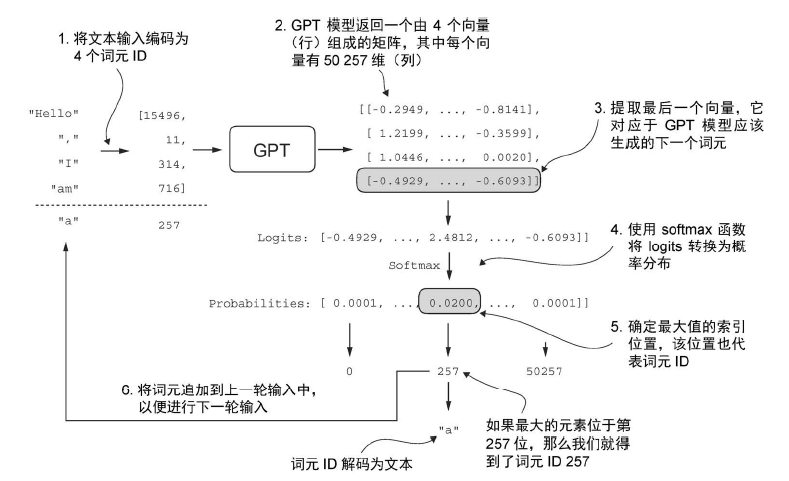
大模型在每次生成文本时,需要把上一次预测的结果添加到上下文中,然后再进行生成。在每一步中,模型输出一个矩阵,其中的向量表示有可能的下一个词元。将与下一个词元对应的向量提取出来,并通过 softmax 函数转换为概率分布。在包含这些概率分数的向量中,找到最高值的索引,这个索引对应于词元ID。然后将这个词元 ID 解码为文本,生成序列中的下一个词元。最后,将这个词元附加到之前的输入中,形成新的输入序列,供下一次迭代使用。这个逐步的过程使得模型能够按顺序生成文本,从最初的输入上下文中构建连贯的短语和句子。
以下的 generate_text_simple 函数实现了贪心解码(greedy decoding),这是一种简单且快速的文本生成方法。
在贪心解码中,模型在每一步选择具有最高概率的词(或标记)作为下一个输出(由于最高的 logit 值对应最高的概率,实际上我们不需要显式地计算 softmax 函数)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def generate_text_simple (model, idx, max_new_tokens, context_size ): for _ in range (max_new_tokens): idx_cond = idx[:, -context_size:] with torch.no_grad(): logits = model(idx_cond) logits = logits[:, -1 , :] probas = torch.softmax(logits, dim=-1 ) idx_next = torch.argmax(probas, dim=-1 , keepdim=True ) idx = torch.cat((idx, idx_next), dim=1 ) return idx