![image]()
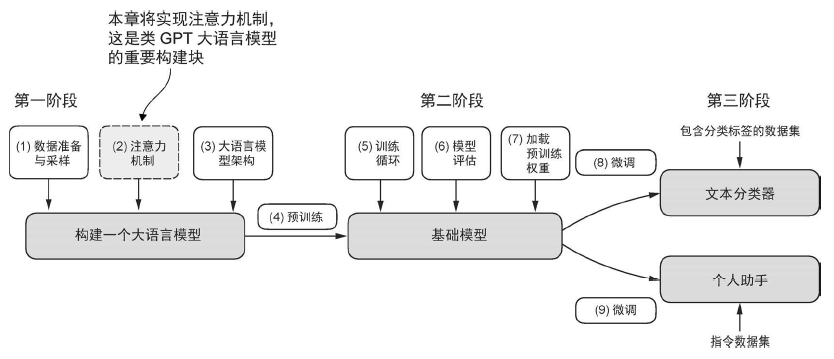
长序列建模中的问题
想要开发一个将文本从一种语言翻译成另一种语言的语言翻译模型。由于源语言和目标语言的语法结构不同,我们无法简单地逐个单词进行翻译。为了处理这个问题,通常使用一个包含编码器和解码器两个子模块的深度神经网络。编码器首先读取和处理整个文本,解码器则负责生成翻译后的文本。
编码器-解码器RNN 的一个主要限制是,在解码阶段,RNN 无法直接访问编码器中的早期
隐藏状态。因此,它只能依赖当前的隐藏状态,这个状态包含了所有相关信息。这可能导致上下文丢失,特别是在复杂句子中,依赖关系可能跨越较长的距离。
使用注意力机制捕捉数据依赖关系
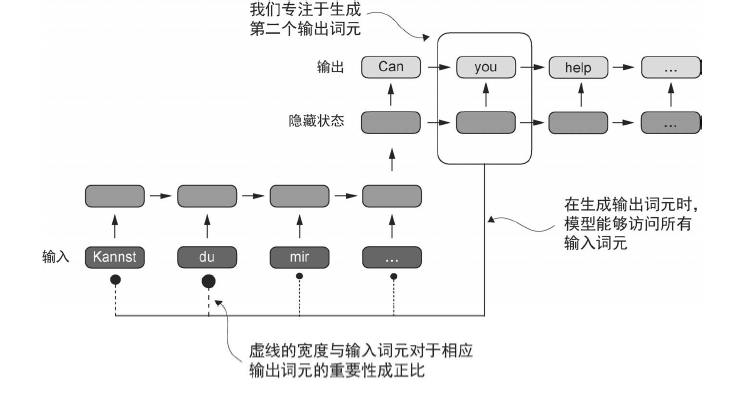
Bahdanau 注意力机制: 对编码器-解码器RNN 进行了修改,使得解码器在每个解码步骤中可以选择性地访问输入序列的不同部分
![image]()
通过自注意力机制关注输入的不同部分
没有可训练权重的简单自注意力机制
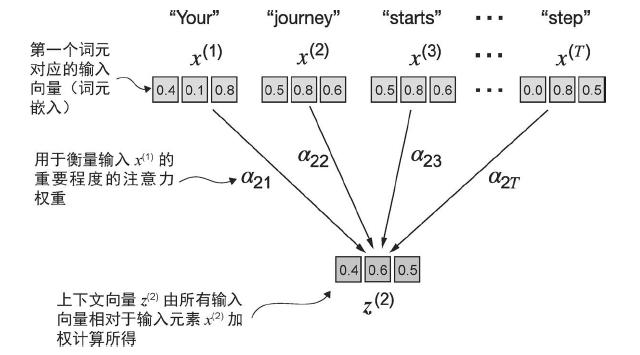
自注意力机制的目标是为每个输入元素计算一个上下文向量,该向量结合了其他所有输入元素的信息:
![image]()
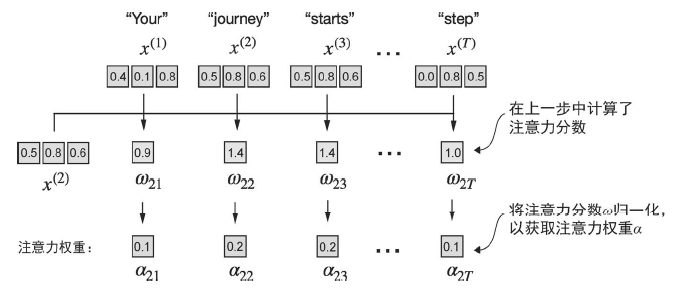
首先使用相似度来计算注意力分数,然后进行归一化:
![image]()
实现带可训练权重的自注意力机制
带有可训练权重的自注意力机制是建立在先前概念之上的:我们希望将上下文向量计算为某个特定输入元素对于序列中所有输入向量的加权和。最显著的区别是这里引入了在模型训练期间更新的权重矩阵。这些可训练的权重矩阵至关重要,这样模型(特别是模型内部的注意力模块)才能学会产生“好的”上下文向量。
逐步计算注意力权重
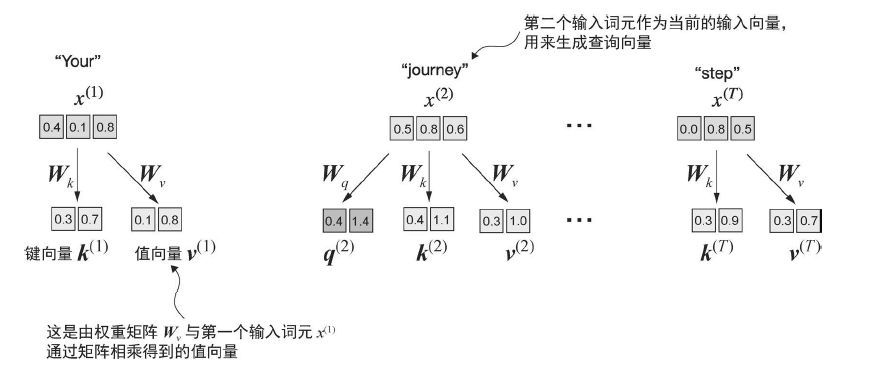
引入三个矩阵:
![image]()
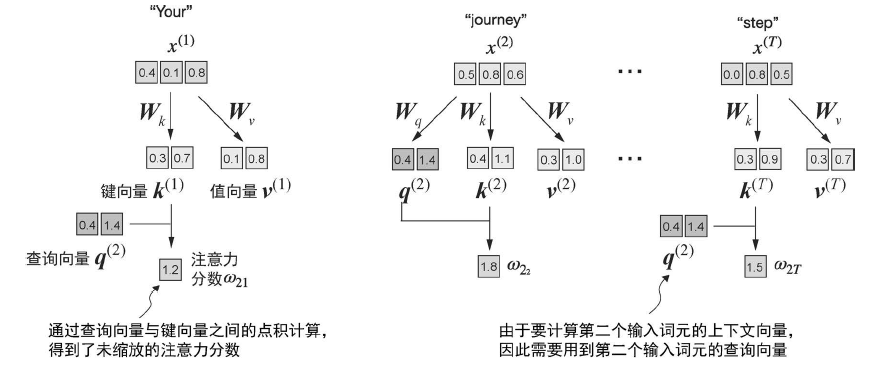
然后计算注意力分数,这里以第二个单词作为查询:
![image]()
然后将注意力权重除以 key 维度的平方根来进行缩放:
- 当输入值非常大时,softmax 输出会非常接近 one-hot(即几乎只有一个元素是 1,其余接近 0)。
- 这意味着在反向传播时,梯度会非常小(接近 0),导致学习信号几乎消失;模型更新困难,甚至出现训练停滞(training stall)
- 为什么要用 softmax?
- softmax 比线性归一化更“鲁棒”和“表达性更强”:它能自动把任意实数分数映射到正的概率分布中,并通过指数放大高分项、压低低分项
- 从而实现真正的“注意力分配”,而不是平均分配。
实现一个简化的自注意Python 类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class attention(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
|
接下来,我们将改进自注意力机制,重点是在机制中引入因果机制和多头机制。因果机制的作用是调整注意力机制,防止模型访问序列中未来的信息,这在语言建模等任务中尤为重要,因为每个词的预测只能依赖之前出现的词。
利用因果注意力隐藏未来词汇
希望自注意力机制在预测序列中的下一个词元时仅考虑当前位置之前的词元。
![image]()
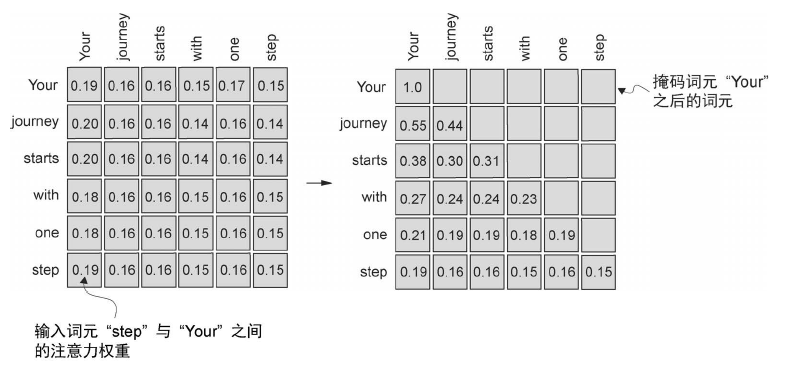
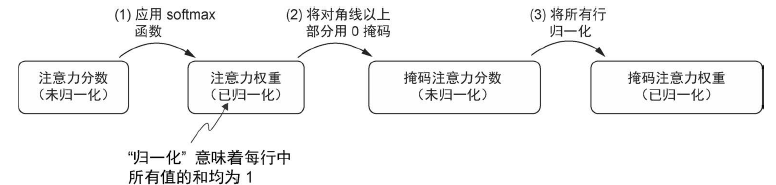
因果注意力的掩码实现
具体步骤如下,注意在经过 softmax 后再进行 mask,然后再归一化:
![image]()
1
2
3
4
5
| context_length = attn_scores.shape[0]
mask_simple = torch.tril(torch.ones(context_length, context_length))
masked_simple = attn_weights * mask_simple
row_sums = masked_simple.sum(dim=-1, keepdim=True)
masked_simple_norm = masked_simple / row_sums
|
进一步改进:softmax 函数会将其输入转换为一个概率分布。当输入中出现负无穷大值(–∞)时,softmax 函数会将这些值视为零概率。(从数学角度来看,这是因为e^–∞无限接近于 0)。可以通过创建一个对角线以上是1 的掩码,并将这些1 替换为负无穷大(-inf)值,来实现这种更高效的掩码“方法”:
![image]()
1
2
3
4
5
| mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)
masked = attn_scores.masked_fill(mask.bool(), -torch.inf)
attn_weights = torch.softmax(masked / keys.shape[-1]**0.5, dim=-1)
|
torch.triu 取上三角(Upper triangular)(上三角为负无穷), torch.tril 取下三角(Lower triangular)(下三角定义为 1)
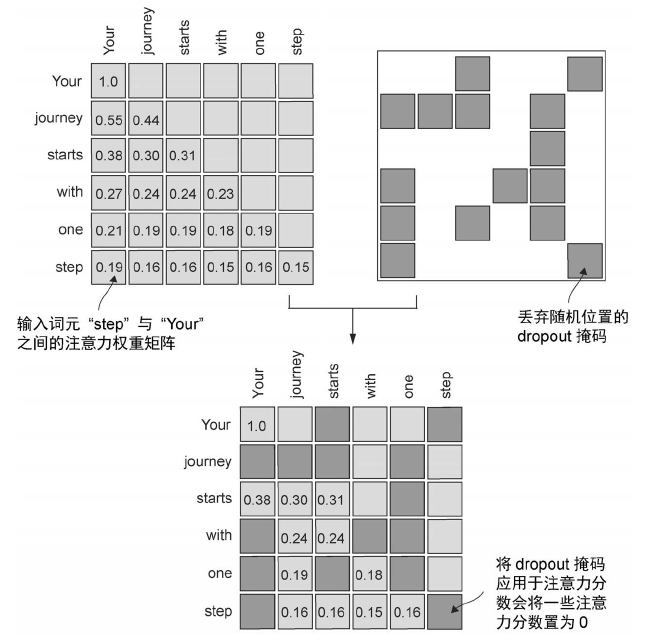
利用dropout 掩码额外的注意力权重
dropout 是深度学习中的一种技术,通过在训练过程中随机忽略一些隐藏层单元来有效地“丢弃”它们。这种方法有助于减少模型对特定隐藏层单元的依赖,从而避免过拟合。需要强调的是,dropout 仅在训练期间使用,训练结束后会被取消。
在Transformer 架构中,一些包括GPT 在内的模型通常会在两个特定时间点使用注意力机制中的dropout:一是计算注意力权重之后,二是将这些权重应用于值向量之后。我们将在计算注意力权重之后应用dropout 掩码,因为这是实践中更常见的做法。
![image]()
实现一个简化的因果注意力类
总结上述内容,现在我们将把因果注意力和dropout 修改应用到前面实现的 attention 类中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| class attention(nn.Module):
def __init__(self, d_in, d_out, dropout, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
'mask',
torch.tril(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_scores.masked_fill_(mask == 0, -inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
|
几个关键点:
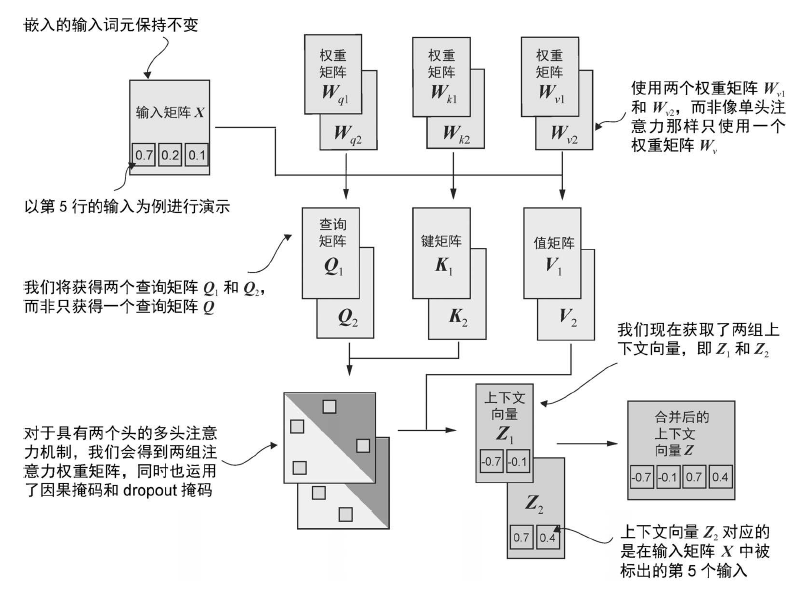
将单头注意力扩展到多头注意力
在本节中,我们将进行最后一步操作,即把先前实现的因果注意力类扩展到多个头上。这也被称为多头注意力。“多头”这一术语指的是将注意力机制分成多个“头”,每个“头”独立工作。在这种情况下,单个因果注意力模块可以被看作单头注意力,因为它只有一组注意力权重按顺序处理输入。
叠加多个单头注意力层
![image]()
这里简单复用了前面的 attention 类,但是输出就会翻倍(因为是直接将标准的 attention 的输出重叠在一起)。所以如果嵌入维度为 4,则需要手动将 dout 设置为 2,来减半维度
1
2
3
4
5
6
7
8
9
10
11
12
13
| class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
self.heads = nn.ModuleList(
[attention(d_in, d_out, context_length, dropout, qkv_bias)
for _ in range(num_heads)]
)
def forward(self, x):
return torch.cat([head(x) for head in self.heads], dim=-1)
|
通过权重划分实现多头注意力
编写一个独立的 MultiHeadAttention 类来实现相同的功能。
- 在这个独立的
MultiHeadAttention 类中,我们不会将单个注意力头进行拼接。
- 相反,我们会创建独立的 W_query、W_key 和 W_value 权重矩阵,并将它们拆分为每个注意力头的单独矩阵:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, num_heads, dropout):
super().__init__()
assert d_out % num_heads == 0
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.w_q = nn.Linear(d_in, d_out, False)
self.w_k = nn.Linear(d_in, d_out, False)
self.w_v = nn.Linear(d_in, d_out, False)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def foward(self, x):
b, seq_len, d_in = x.shape
query = self.w_q(x)
key = self.w_k(x)
value = self.w_v(x)
query = query.view(b, seq_len, self.num_heads, self.head_dim)
key = key.view(b, seq_len, self.num_heads, self.head_dim)
value = value.view(b, seq_len, self.num_heads, self.head_dim)
query = query.transpose(1, 2)
key = key.transpose(1, 2)
value = value.transpose(1, 2)
attn_scores = query * key.transpose(2, 3)
mask_bool = self.mask.bool()[:seq_len, :seq_len]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vec = (attn_weights @ values).transpose(1, 2)
context_vec = context_vec.contiguous().view(b, seq_len, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vec
|
注意的点:
self.head_dim = d_out // num_heads 这里要使用 //,因为 / 无论结果是否能除尽,都会返回 float;此外,还在最前面有一个断言,即要求输出的维度可以整除注意力头的数量)(因为要分割映射矩阵)- 计算完三个向量后需要进行转置,这是为了方便计算
- 计算注意力分数的时候要注意 key 转置的维度
- contiguous() 会在内存中重新排列数据,让元素真正按行存放。