
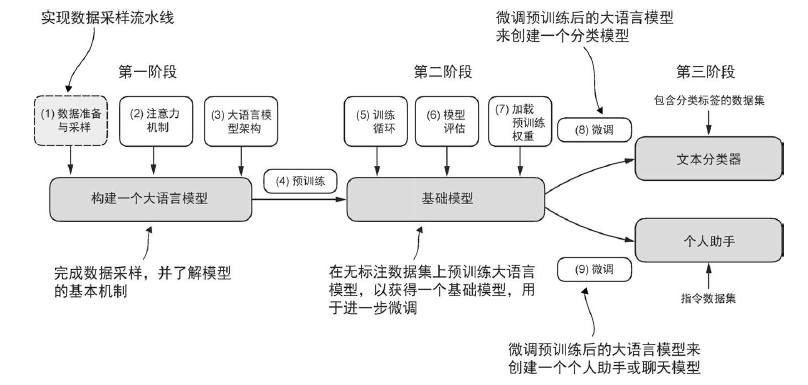
理解词嵌入
包括大语言模型在内的深度神经网络模型无法直接处理原始文本。由于文本数据是离散的,因此我们无法直接用它来执行神经网络训练所需的数学运算。我们需要一种将单词表示为连续值的向量格式的方法。
目前,人们已经开发出多种算法和框架来生成词嵌入,其中word2vec 是早期最流行的方法之一。通过训练神经网络架构,word2vec 实现了根据目标词预测上下文,或根据上下文预测目标词,从而生成词嵌入。word2vec 的核心思想是,出现在相似上下文中的词往往具有相似的含义。
文本分词
词元既可以是单个单词,也可以是包括标点符号在内的特殊字符。一个简单的方法是通过标点符号和空格来进行划分。
将词元转换为词元 ID
分词器通常包含两个常见的方法:encode 方法和 decode 方法。encode 方法接收文本样本,将其分词为单独的词元,然后再利用词汇表将词元转换为词元 ID。而 decode 方法接收一组词元ID,将其转换回文本词元,并将文本词元连接起来,形成自然语言文本
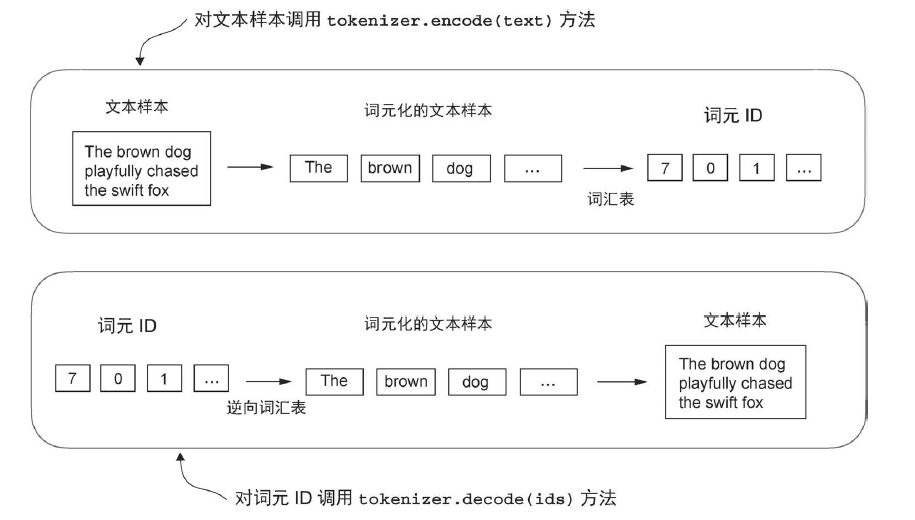
代码如下:
1 | class SimpleTokenizerV1:#一个实例的名字创立 |
但是某些单词可能没有出现过?
引入特殊上下文词元
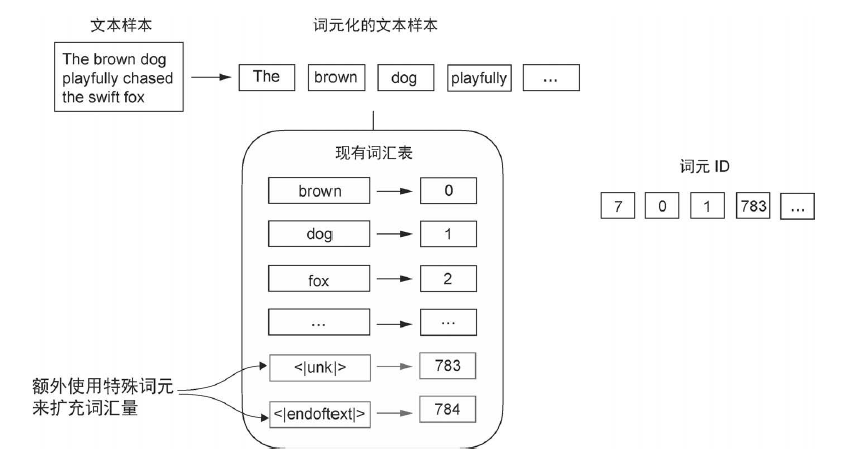
修改分词器,使其在遇到词汇表中不存在的单词时,使用特殊词元 <|unk|> 代替。此外,还会在不相关的文本之间插入特殊词元。例如,在训练类GPT 大语言模型时,如果使用多个独立的文档或图书作为训练材料,那么通常会在每个文档或图书的开头插入一个词元,以区分前一个文本源。这种做法有助于模型理解,尽管这些文本源在训练时是连接在一起的,但它们实际上是相互独立的。
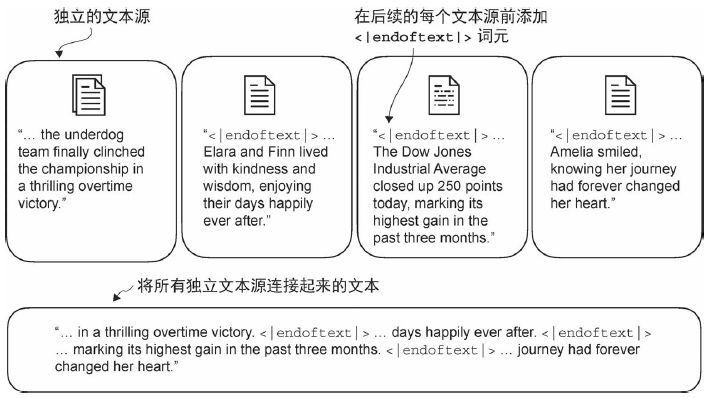
代码如下:
1 |
|
修改后的 tokenizer 为:
1 | class SimpleTokenizerV2:##版本2.0,启动! |
额外的 token:
- [BOS](序列开始):标记文本的起点,告知大语言模型一段内容的开始。
- [EOS](序列结束):位于文本的末尾,类似 <|endoftext|>,特别适用于连接多个不相关的文本。例如,在合并两篇不同的维基百科文章(或两本不同的图书)时,[EOS] 词元指示一篇文章的结束和下一篇文章的开始。
- [PAD](填充):当使用批次大小(batch size)大于1 的批量数据训练大语言模型时,数据中的文本长度可能不同。为了使所有文本具有相同的长度,较短的文本会通过添加 [PAD] 词元进行扩展或“填充”,以匹配批量数据中的最长文本的长度。
值得注意的是,GPT 模型使用的分词器并不依赖这些特殊词元,而是使用 <|endoftext|> 词元来简化其处理流程。<|endoftext|> 词元与 [EOS] 词元作用相似。此外,<|endoftext|> 也被用于文本的填充。然而,正如本书后面章节中将要探讨的那样,当模型在批量输入上进行训练时,我们通常使用掩码技术,这意味着我们并不会关注那些仅用于填充的词元。因此,具体选择哪种词元来进行填充实际上并不重要。
此外,GPT 模型的分词器也不使用 <|unk|> 词元来处理超出词汇表范围的单词,而是使用 BPE 分词器将单词拆解为子词单元。
BPE
BPE (Byte Pair Encoding) 分词器可以正确地编码和解码未知单词,比如“someunknownPlace”。BPE 分词器是如何做到在不使用 <|unk|> 词元的前提下处理任何未知词汇的呢?
BPE 算法的原理是将不在预定义词汇表中的单词分解为更小的子词单元甚至单个字符,从而能够处理词汇表之外的单词。因此,得益于 BPE 算法,如果分词器在分词过程中遇到不熟悉的单词,它可以将其表示为子词词元或字符序列:
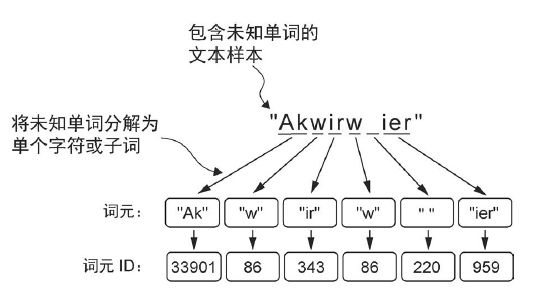
简单来说,BPE 通过将频繁出现的字符合并为子词,再将频繁出现的子词合并为单词,来迭代地构建词汇表。具体来说,BPE 首先将所有单个字符(如 “a”, “b” 等)添加到词汇表中。然后,它会将频繁同时出现的字符组合合并为子词。例如,“d” 和 “e”可以合并为子词“de”,这是 “define”, “depend”, “made”, “hidden” 等许多英语单词中的常见组合。字符和子词的合并由一个频率阈值来决定。
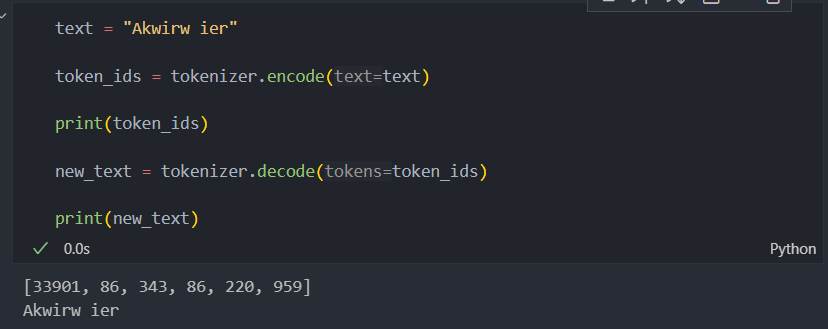
例子:尝试使用 tiktoken 库中的 BPE 分词器对未知单词“Akwirw ier”进行分词,并打印所有 token ID。然后,对这些词元ID 调用 decode 方法,检查它能否还原原始输入“Akwirw ier”。
使用滑动窗口进行数据采样
大语言模型通过预测文本序列的下一个单词来进行预训练:

可以使用滑动窗口来实现:
1 | from torch.utils.data import Dataset, DataLoader |
- 过多的重叠可能导致过拟合,可以增加步幅
创建词元嵌入
嵌入层实质上执行的是一种查找操作,它根据词元 ID 从嵌入层的权重矩阵中检索出相应的行。
本质上可以将嵌入层方法视为一种更有效的实现独热编码的方法。它先进行独热编码,然后在全连接层中进行矩阵乘法,这在本书的补充代码中有所说明。由于嵌入层只是独热编码和矩阵乘法方法的一种更高效的实现,因此它可以被视为一个能够通过反向传播进行优化的神经网络层。
编码单词位置信息
绝对位置嵌入(absolute positional embedding)直接与序列中的特定位置相关联。对于输入序列的每个位置,该方法都会向对应词元的嵌入向量中添加一个独特的位置嵌入,以明确指示其在序列中的确切位置。例如,序列中的第一个词元会有一个特定的位置嵌入,第二个词元则会有另一个不同的位置嵌入,以此类推。
相对位置嵌入(relative positional embedding)关注的是词元之间的相对位置或距离,而非它们的绝对位置。这意味着模型学习的是词元之间的“距离”关系,而不是它们在序列中的“具体位置”。这种方法使得模型能够更好地适应不同长度(包括在训练过程中从未见过的长度)的序列。