【LLM-basic】1-KV Cache

KV Cache 是什么
KV Cache(Key–Value Cache) 指的是在 Transformer 自注意力(Self-Attention) 推理过程中,对每一层生成的 Key (K) 和 Value (V) 向量进行缓存(cache),从而避免在生成下一个 token 时重复计算前面所有的注意力输入。
下图是大模型生成下一个 token 的过程。生成一个 token 后,将其放到序列的末尾,继续生成下一个 token。该 token 对应的 attention 表示生成下一个 token 需要关注哪些以前的 token(受哪些 token 影响)。

解码器是因果的(即,一个标记的注意力仅取决于其前面的标记),因此在每个生成步骤中,我们都在重新计算同一个先前标记的注意力,而我们实际上只想计算新标记的注意力。
注意下面这个图:
- 第一步:Q1 和 K1 计算 attention(只有 Q1K1),表示生成 token1 只需要关注 token0(Q1 和 K1 由 token0 计算而来,用于生成 token1)
- 第二步:token1 生成后,得到 Q2 和 K2,此时计算 attention(Q2K1 和 Q2K2 两个值),分别表示生成 token2 需要关注 token0 和 token1。后续以此类推。
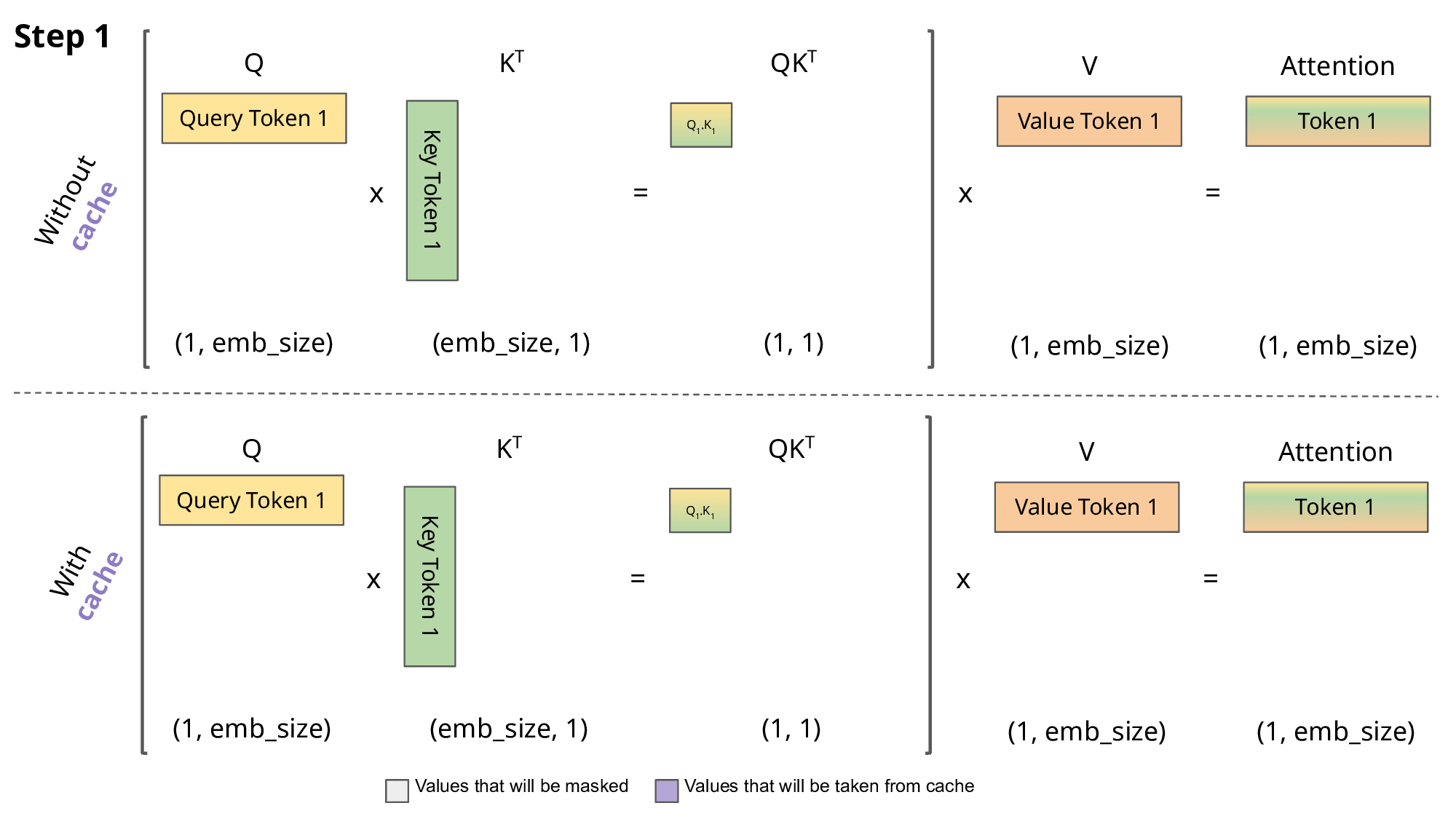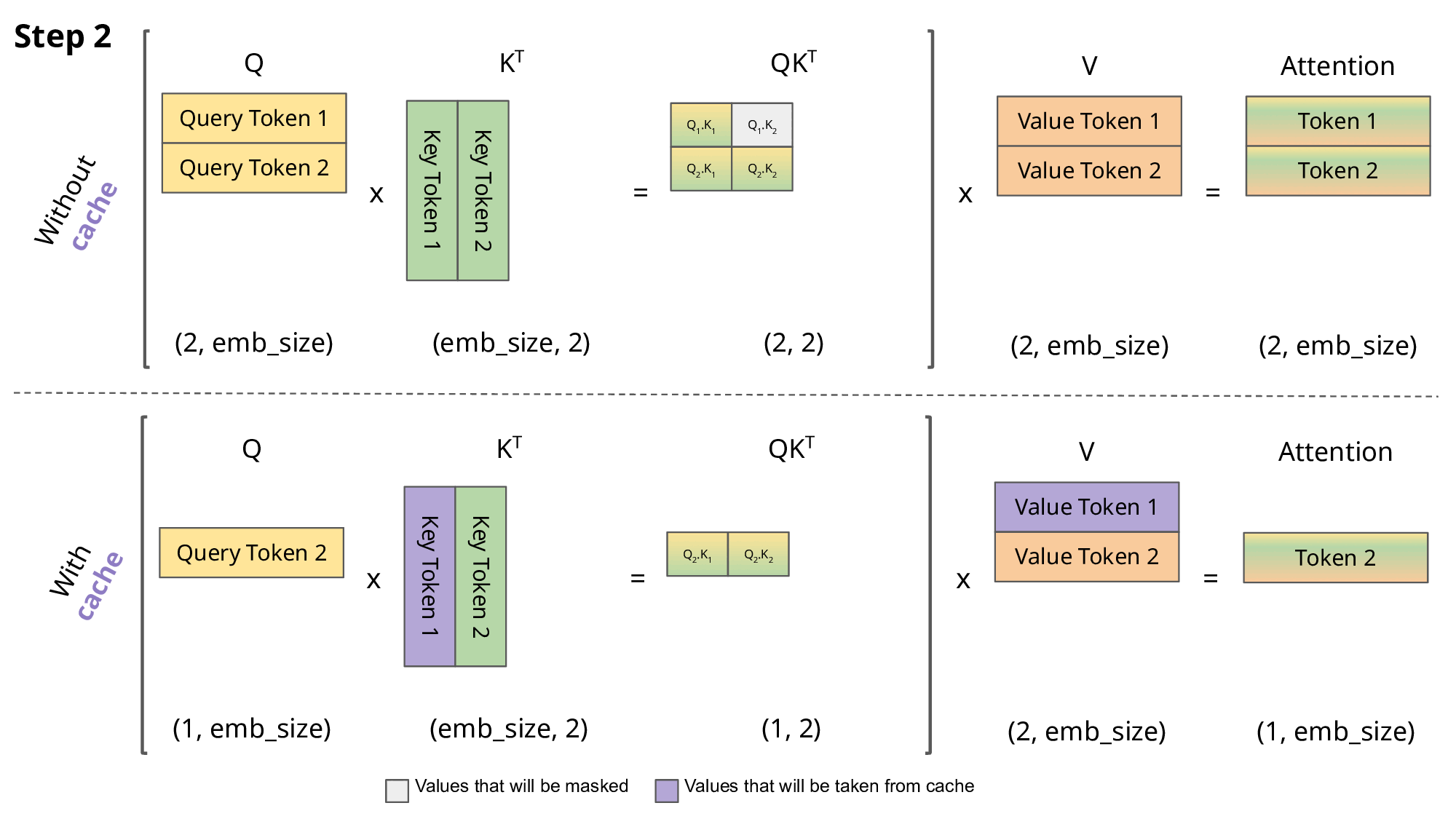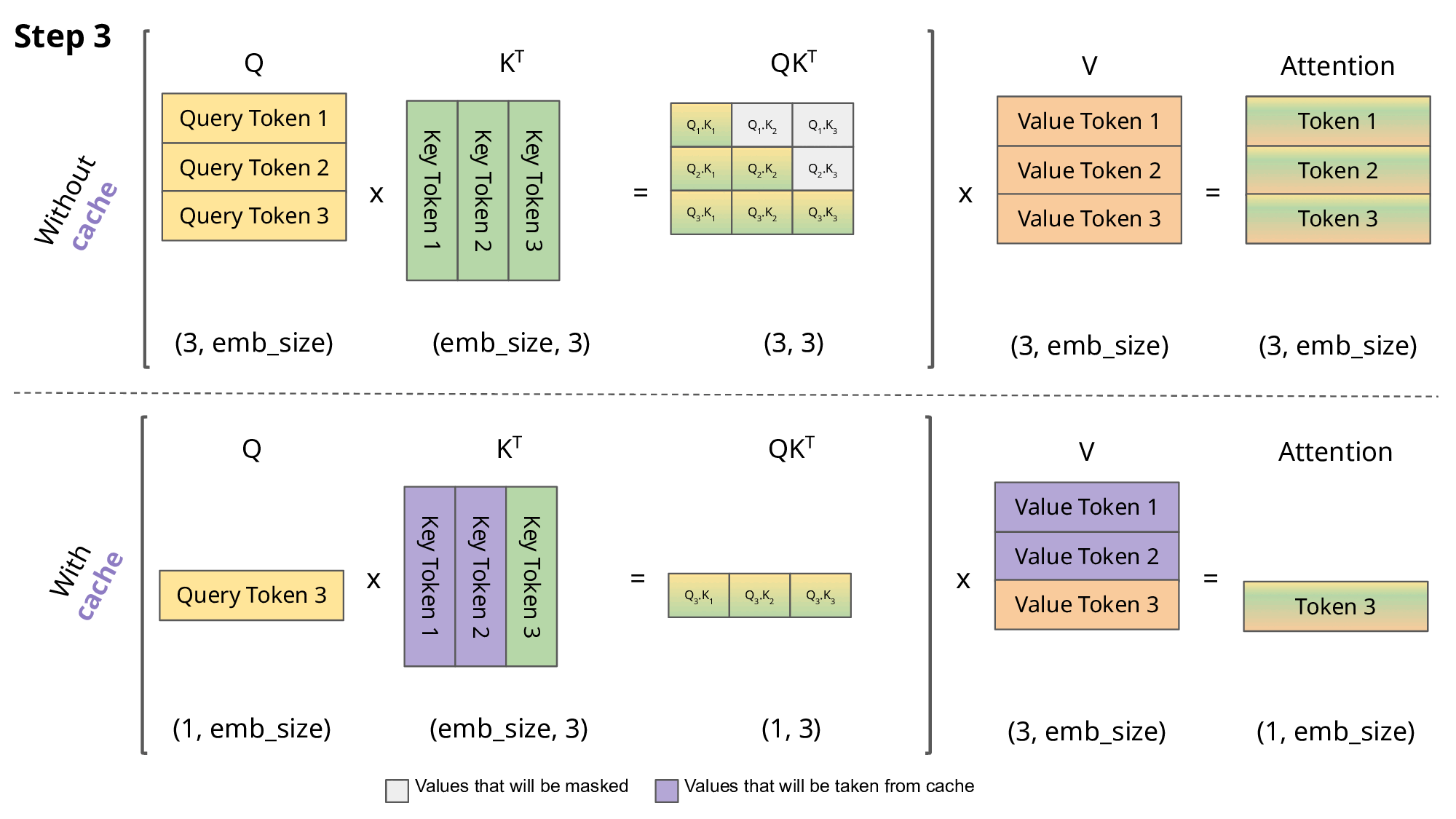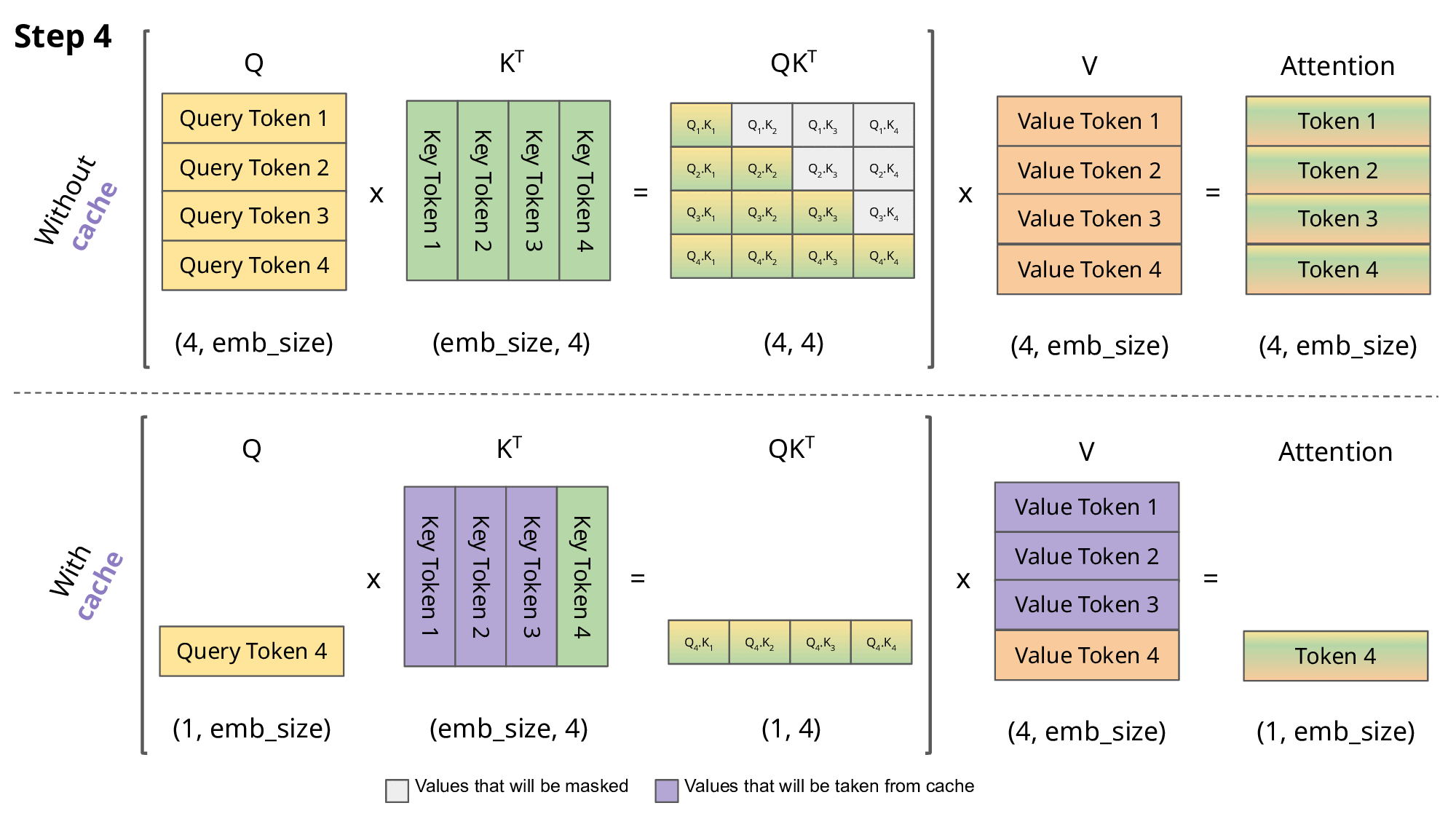
如果不使用 KV Cache,那么每次都需要计算先前的 K 和 V。
为什么不 cache Q?
注意,生成新的 token X 只需要上一步 token X-1 对应位置计算出的 attention。例如,在生成 token2 时,只需要 token0 和 token1,对应的 attention 为 Q2K1 和 Q2K2。可以发现,此时不需要之前的 Q1,只需要之前的 K1 和当前的 K2。
核心原因还是只需要当前 token 对应的 attention 即可(对应到 attention map 的左下角部分)。