
Solve short hands-on challenges to perfect your data manipulation skills. Click here for more information.
创建、读和写
You can’t work with data if you can’t read it. Get started here.
开始
导入 pandas:
1 | import pandas as pd |
创建数据
Pandas 中的两个核心对象:DataFrame 和 Series。
DataFrame
DataFrame 是一个表。它包含一个单独条目(entry)的数组,每个条目都有一个特定的值。每个条目对应一行(或记录)和一列。例如:
1 | pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}) |
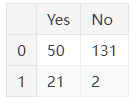
在本例中,“0,No” 条目的值为 131 。“0,Yes” 条目的值为 50,以此类推。数据框条目不限于整数。例如,下面是一个值为字符串的DataFrame:
1 | pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']}) |
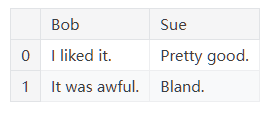
我们使用 pd.DataFrame() 构造函数来生成这些 DataFrame 对象。声明一个新对象的语法是一个字典,它的键是列名(本例中是Bob和Sue),它的值是一个条目列表。这是构造新 DataFrame 的标准方法。
字典列表构造函数将值赋给列标签,但对行标签来说,默认是从 0 开始的升序计数。
DataFrame 中使用的行标签列表称为索引。可以通过在构造函数中使用 index 形参给它赋值:
1 | pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], |

Series
相比之下,序列是数据值的序列。如果 DataFrame 是一个表,那么 Series 就是一个列表。只需要一个列表就可以创建一个 Series 对象:
1 | pd.Series([1, 2, 3, 4, 5]) |

从本质上讲,Series 是 DataFrame 的一列。因此,可以像以前一样使用 index 参数将行标签分配给 Series。但是, Series 没有列名,它只有一个总称:
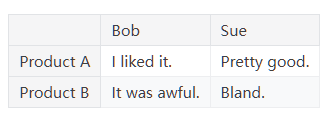
1 | pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A') |
读取数据
数据可以以许多不同的形式和格式中的任何一种进行存储。到目前为止,其中最基本的是 CSV 文件。当你打开一个 CSV 文件时,你会看到这样的东西:
1 | Product A,Product B,Product C, |
CSV 文件本质上是一个用逗号分隔的值表。因此得名:Comma-Separated Values,CSV。
读取并查看 CSV 文件:
1 | import pandas as pd |
索引、选择和赋值
Pro data scientists do this dozens of times a day. You can, too!
原生访问器
原生 Python 对象提供了索引数据的方法。Pandas包含了所有这些内容:
1 | df = pd.read_csv('file.csv') |
Pandas 中的索引
Pandas 有自己的索引方式 loc 。Pandas 索引的工作方式有两种。
基于索引的选择
iloc 基于数值位置选择数据。例如访问第一行的数据:
1 | df.iloc[0] |
loc 和 iloc 都是行优先,这意味着检索行稍微容易一些,而获取检索列稍微困难一些。例如访问第一列的数据:
1 | df.iloc[:, 0] |
更多例子:
1 | # 访问第二行和第三行的第一列 |
基于标签的选择
iloc 在概念上比 loc 简单,因为它忽略数据集的索引。
当使用 iloc 时,我们将数据集视为一个大矩阵(列表的列表),我们必须根据位置对其进行索引。
相比之下,loc 使用索引中的信息来完成工作。由于数据集通常包含有意义的索引,因此使用loc通常更容易。
例如,访问所有行的以下属性:
1 | df.loc[:, ['taster_name', 'taster_twitter_handle', 'points']] |
loc 还是 iloc ?
- iloc 使用标准的索引策略,
0:10的结果是0,...,9,而 loc 的结果是0,...,10。 - loc 可以这样用:
df.loc['a':'d'],表示索引标签 a 到 d 之间的所有列。(包括 d) - iloc 索引数值位置,loc 索引标签,且 loc 包括“结尾”。
操作索引
Pandas 默认使用数字作为索引,可以通过 set_index() 将指定列设置为索引:
1 | df = df.set_index("title") |
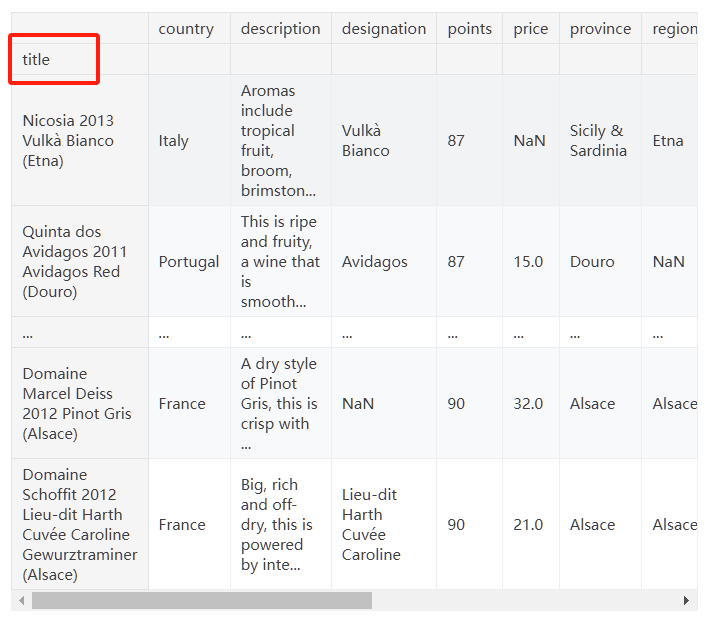
注意,重新设置索引之后要进行赋值。即不会在原来的基础上进行修改,而是会返回一个新的 DataFrame 对象。
条件选择
例如,假设我们对意大利生产的好于平均水平的葡萄酒特别感兴趣。
我们首先需要检查每一瓶酒是否来自意大利:
1 | df.country == 'Italy' |

这个操作会返回一个全是布尔变量的 Series 对象。表示该行的 country 属性是否为 Italy 。
接下来可以通过 loc 来选择对应的行:
1 | df.loc[df.country == 'Italy'] |
可以使用 & 或者 | 来携带多个条件:
1 | df.loc[(df.country == 'Italy') & (reviews.points >= 90)] |
此外,pandas 还提供了一些内置的选择器:isin() 和 isnull()
isin() 选择那些值在给定列表里的数据。例如选取包含意大利和法国的行:
1 | df.loc[df.country.isin(['Italy', 'France'])] |
isnull() 选择那些包含空值的行:
1 | df.loc[df.price.isnull()] |
赋值
给一整列赋值:
1 | # 将整列都赋值为 everyone |
总结函数和映射
Extract insights from your data.
总结函数
使用 describe() 方法获取对数据的高级描述: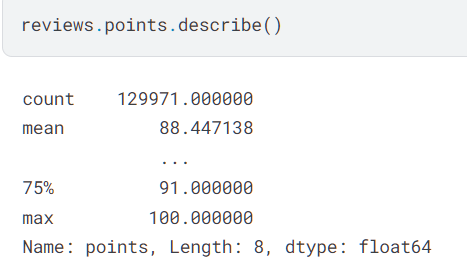
对不同的数据类型,会有不同的总结,例如对字符串: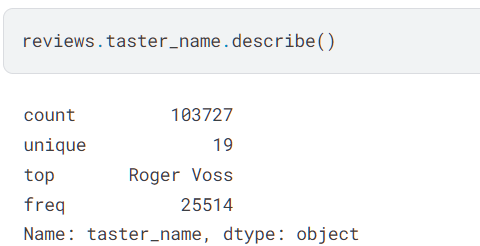
mean() 方法:查看某一列的平均值。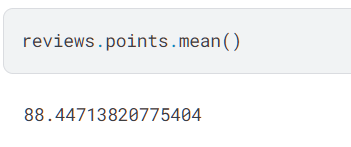
unique() 方法:查看某一列的唯一值列表。(对应于 describe 输出的 unique 关键字)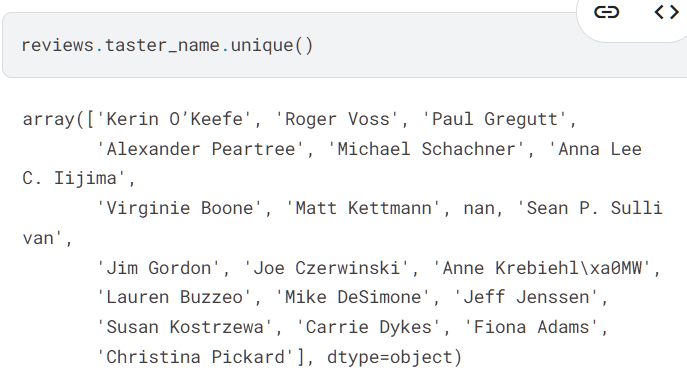
count() 方法:查看某一列的唯一值列表以及其出现次数。
映射(Maps)
批量修改某些列。
例如,想要将某一列减去其均值:
1 | review_points_mean = reviews.points.mean() |
传递给 map() 的函数应该期望得到来自 Series 的单个值(在上面的示例中是一个点值,即 p),并返回该值的转换版本(即 p - review_points_mean)。map()返回一个新的 Series ,其中所有的值都已被函数转换过。
这里 lambda 表示匿名函数,其等价于以下函数:
1 | def my_function(p): |
同样地, apply() 方法同样可以实现上述过程:
1 | def remean_points(row): |
此外,也可以直接使用操作符 + 、 - 等直接对 Series 对象进行操作,这比上述两个函数更高效,但是不支持更复杂的情况。
分组和排序
Scale up your level of insight. The more complex the dataset, the more this matters
分组分析
以下代码等同于 value_counts() 方法:
1 | reviews.groupby('points').points.count() |
即按照 points 列进行分组,分组之后再对 point 列进行计数。
1 | reviews.groupby('points').price.min() |
上述代码按照 points 列进行分组,分组之后,在每个组里面计算最小值。
生成的每个组可以视为 DataFrame 的一个片段,其中仅包含具有匹配值的数据。可以直接使用 apply() 方法访问这个 DataFrame,然后可以通过任何方式操作数据。例如,下面是从数据集中的每个酒厂中选择第一个被评论的葡萄酒名称的一种方法:
1 | reviews.groupby('winery').apply(lambda df: df.title.iloc[0]) |
对于更细粒度的,还可以按多个列分组。举个例子,以下是我们如何按国家和省份挑选最好的葡萄酒:
1 | reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()]) |
排序
简单排序(默认升序):
1 | countries_reviewed.sort_values(by='len') |
按照多个列进行排序:
1 | countries_reviewed.sort_values(by=['country', 'len']) |
数据类型和缺失值
Deal with the most common progress-blocking problems
数据类型
DataFrame 或Series 中每列的数据类型称为 dtype 。可以使用 dtype 属性获取特定列的类型。
1 | reviews.price.dtype |
dtypes 属性返回 DataFrame 中每一列的数据类型。
1 | reviews.dtypes |
注意,字符串的类型为 object 。
可以使用 astype() 方法进行数据转换:
1 | reviews.points.astype('float64') |
缺失值
使用 fillna() 方法来替换缺失值。通常可以设置为“unkonwn”字符串,便于后续更改。这种值通常被称作“哨兵”,还包括“Undisclosed”、“Invalid”等。
此外可以使用 replace() 方法来替换设置的哨兵值。
重命名和组合
Data comes in from many sources. Help it all make sense together
重命名
有时需要更改列明或索引名。
1 | # 将 points 列更名为 score |
组合
组合来自多个 DataFrame 或 Series 的数据。
例如,两个 CSV 文件有相同的列,最简单的方法是 conca() 。
1 | canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv") |
例如,组合两个具有相同索引的 CSV 文件:
1 | left = canadian_youtube.set_index(['title', 'trending_date']) |
lsuffix 和 rsuffix 参数用于区分两个相同的列。
简单读写 CSV 文件
读
1 | import pandas as pd |
写
1 | for i, row in df.iterrows(): |
新建
1 | data = { |
loc 方法
定位某一行
1 | path = df.loc[index]['path'] |
定位某列的指定值
1 | df = df.loc[df['label'] == 'Normal'] |