
Learn the core ideas in machine learning, and build your first models. Click here for more information.
模型是如何工作的?
The first step.
引入
考虑以下场景:
- 你表弟做房地产投机赚了几百万美元。因为你对数据科学感兴趣,他提出要和你成为商业伙伴。他会提供钱,你会提供模型来预测各种房子的价值。
- 你问你的堂兄他过去是如何预测房地产价值的,他说这只是直觉。但更多的质疑表明,他从过去看过的房子中识别出了价格模式,并用这些模式来预测他正在考虑的新房。
- …
考虑这个简单的决策树: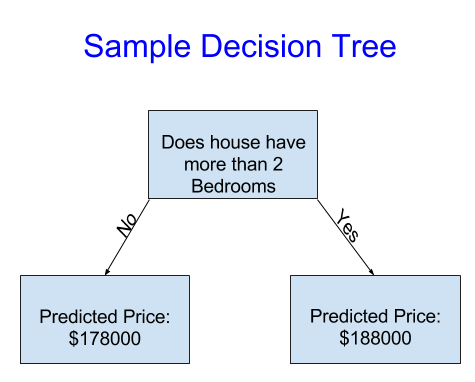
它只把房子分成两类。所考虑的任何房屋的预测价格都是同一类别房屋的历史平均价格。
通过数据来决定如何将房屋分为两类,同时决定其预测价格。从数据中捕获模式的这一步称为拟合(fitting)或训练(training)模型。用于拟合模型的数据称为训练数据(training data)。
改进决策树
以下哪个决策树更有效?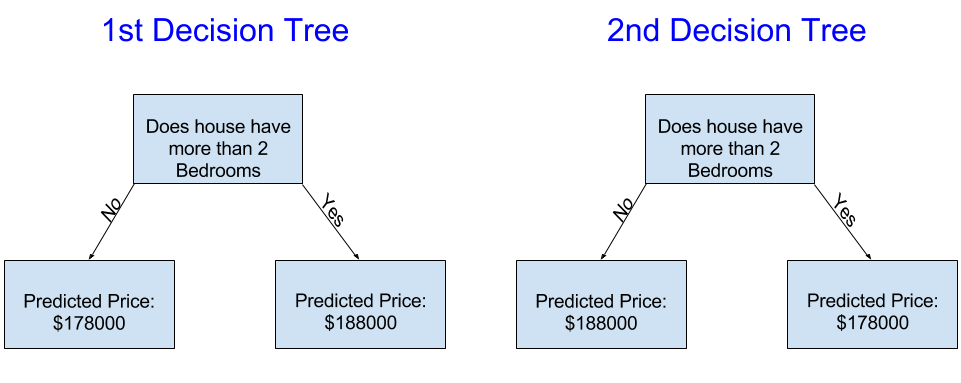
左边的决策树(决策树1)可能更有意义,因为它抓住了一个现实,即卧室多的房子往往比卧室少的房子卖得更高。这种模式最大的缺点是,它没有考虑到影响房价的大多数因素,比如浴室数量、地块大小、位置等。
可以使用具有更多“分裂”的树来捕获更多因素。这些树被称为“更深的”树。考虑到每栋房子地块总面积的决策树可能是这样的: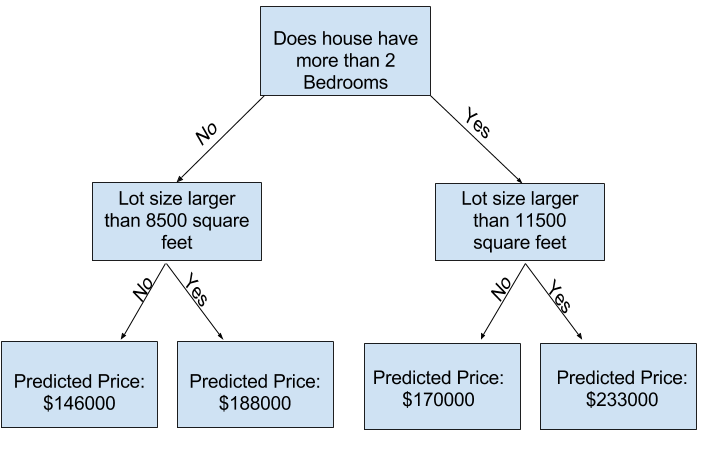
房子的预测价格在这棵树的底部。我们做出预测的底部点被称为叶子 (leaf)。
初步探索数据
Load and understand your data.
使用 Pandas 来加载数据
Pandas 是数据科学家用来探索和操作数据的主要工具。大多数人在代码中将 pandas 缩写为 pd:
1 | import pandas as pd |
Pandas 库中最重要的部分是 DataFrame。DataFrame 保存了您可能认为是表的数据类型。这类似于 Excel 中的工作表或 SQL 数据库中的表。
使用如下命令来读取 csv 文件,并进行展示:
1 | df = pd.read_csv('my_csv.csv') |
更多关于 pandas 的介绍。
对数据的解释
某个 csv 文件通过 .describe() 展示的结果为: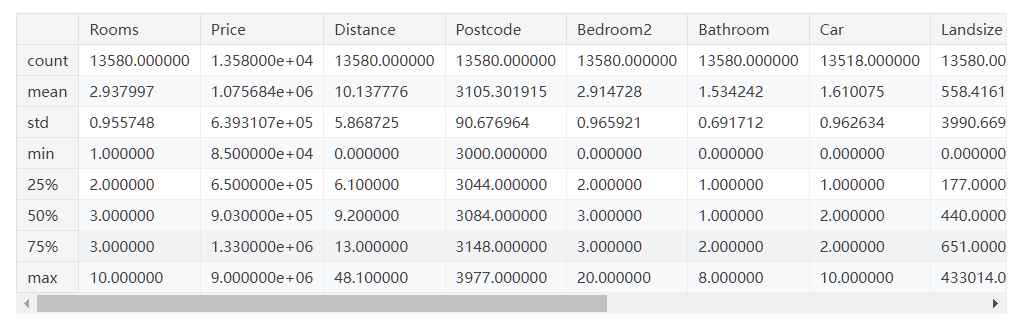
- 结果为原始数据集中的每列显示8个数字。第一个数字是 count,显示有多少行具有非缺失值。
- 缺失值的产生有很多原因。例如,在调查一间卧室的房子时,不会收集第二间卧室的大小。我们将回到丢失数据的话题。
- 第二个值是均值,也就是平均值。在此之下,std 是标准偏差,它衡量数值的数值分布。
- 后续五个值:将该列的数据升序排序形成一个列表,在列表中走四分之一,会发现一个大于 25% 且小于 75% 的值。这是 25% 的定义。
第一个机器学习模型
Building your first model. Hurray!
选择建模的数据
一条数据有很多变量,如何选择合适的变量?我们先用直觉选几个变量。后面的课程将展示自动确定变量优先级的统计技术。
首先需要查看数据集中所有列的列表。通过 DataFrame 的 columns 属性完成:
1 | import pandas as pd |
1 | Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG', |
某些数据可能有缺失值,后续课程会解决缺失值。这里简单地删除有缺失的数据,通过 .dropna():
1 | melbourne_data = melbourne_data.dropna(axis=0) |
注意 .dropna() 不会在当前 DataFrame 上进行修改,而是会返回一个新的对象,所以需要赋值给新对象。
获取 DataFrame 子集的方法:
- 使用点
. - 使用一个列名列表
选择预测目标
通过点 . 来访问某个变量的数据。这些数据存储在一个 Series 中,它大致类似于只有单列数据的 DataFrame 。需要预测的变量为 Price ,定义为y:
1 | y = melbourne_data.Price |
选择特征
“特征”定义为输入模型的数据列,并后续用于预测。使用列名列表来获取,并定义为 x:
1 | melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude' 'Longtitude'] |
使用 .head() 方法查看头部几个样本:
1 | x.head() |
构建模型
使用 scikit-learn 包来创建模型。代码中写作 sklearn。
通过以下步骤来构建模型:
- 定义:模型类型、模型参数
- 拟合(训练):从数据中学习模式
- 预测:Just what it sounds like(原文🤔)
- 评估:确定模型的准确度
一个简单的例子:
1 | from sklearn.tree import DecisionTreeRegressor |
设置 random_state 确保在每一个轮次中获取相同的结果。但是模型的性能和这个数字无关。
现在使用训练好的模型来预测输入的前 5 个数据:
1 | melbourne_model.predict(X.head()) |
模型验证
Measure the performance of your model, so you can test and compare alternatives.
什么是模型验证
许多人在衡量预测准确性时犯了一个巨大的错误。他们用训练数据进行预测,并将这些预测与训练数据中的目标值进行比较。稍后您将看到这种方法的问题以及如何解决它,但让我们先考虑一下如何做这个。
考虑最简单的平均绝对误差(Mean Absolute Error, MAE):
1 | error = actual - predicted |
使用 scikit-learn 计算 MAE:
1 | from sklearn.metrics import mean_absolute_error |
“In-Sample”分数的问题
前面提到的评价方式是一种“样本内”分数(in-sample)。是同统一数据来训练和预测。想象以下场景:
在大型房地产市场中,门的颜色与房价无关。然而,在您用于构建模型的数据样本中,所有带有绿色门的房屋都非常昂贵。这个模型的工作是找到预测房价的模式,所以它会看到这个模式,它总是会预测绿色门的房屋的高价格。由于该模式是从训练数据中导出的,因此该模型在训练数据中会显得准确。但是,如果当模型看到新的数据时,这种模式不成立,那么在实际使用时,模型将非常不准确。
由于模型的实用价值来自于对新数据的预测,因此我们在未用于构建模型的数据上衡量性能。要做到这一点,最直接的方法是从模型构建过程中排除一些数据,然后使用这些数据来测试模型对以前没有见过的数据的准确性。这些数据称为验证数据(validation data)。
Coding it!
scikit-learn 提供了 train_test_solit 方法来划分训练集和测试集。
1 | from sklearn.model_selection import train_test_split |
通过设置 test_size 来更改测试集的比例。
Wow!
经过测试,样本内数据的平均绝对误差约为500美元,而样本外超过25万美元!
欠拟合和过拟合
Fine-tune your model for better performance.
实验不同模型
两个极端
- 当我们把房子分成许多片叶子时,每片叶子上的房子也更少。房子很少的树叶会做出非常接近这些房子的实际价值的预测,但它们对新数据的预测可能非常不可靠(因为每次预测都只基于几所房子)。
- 这是一种被称为过拟合的现象,即模型几乎完美地匹配训练数据,但在验证和其他新数据方面表现不佳。另一方面,如果我们把树画得很浅,它就不会把房子分成很明显的组。
- 如果一棵树只把房子分成2个或4个,每一组仍然有各种各样的房子。对大多数机构来说,结果预测可能还很遥远,甚至在训练数据中也是如此(出于同样的原因,它在验证中也会很糟糕)。
- 当一个模型无法捕捉数据中的重要区别和模式,因此即使在训练数据中也表现不佳,这被称为欠拟合。
例子
通过设置不同数量的决策树结点数量 max_leaf_nodes,计算出不同的精确率。
1 | from sklearn.metrics import mean_absolute_error |
结论
两种情况:
- 过拟合:捕捉未来不会再出现的虚假模式,导致预测不那么准确
- 欠拟合:无法捕捉相关的模式,同样导致预测不准确
随机森林
Using a more sophisticated machine learning algorithm.
引入
决策树留给你一个艰难的决定。有很多叶子的深树会过拟合,因为每个预测都是来自叶子附近的少数房屋的历史数据。但是一棵叶子很少的浅树会表现得很差,因为它无法在原始数据中捕捉到尽可能多的区别。
即使是今天最复杂的建模技术也面临着欠拟合和过拟合之间的紧张关系。但是,许多模型都有聪明的想法,可以带来更好的性能。我们将以随机森林为例。
随机森林使用许多树,它通过平均每个组成树的预测来进行预测。它通常比单一决策树具有更好的预测准确性,并且在默认参数下工作得很好。
1 | from sklearn.ensemble import RandomForestRegressor |
结论
可能还有进一步改进的空间,但这已经比25万的最佳决策树误差有了很大的改进。有一些参数允许你改变随机森林的性能,就像我们改变单个决策树的最大深度一样。但随机森林模型的一个最佳特征是,即使没有这种调整,它们通常也能合理地工作。
机器学习比赛
Enter the world of machine learning competitions to keep improving and see your progress.
It’s your turn!